Вы когда-нибудь ловили себя на том, что смотрите на изображение, заполненное текстом, и мечтаете о том, чтобы его можно было легко извлечь и отредактировать? Будь то отсканированный документ, снимок экрана или фотография доски, ручной ввод текста может занять много времени и привести к ошибкам. Вот тут-то и пригодится DeepSeek — новый и мощный чат-бот на основе ИИ, который можно использовать для упрощения извлечения текста из изображений.
В этом руководстве мы расскажем, как DeepSeek может помочь вам без труда извлекать текст, и познакомим вас с PDFelement — универсальным инструментом, который улучшает ваш рабочий процесс управления документами.
Именно здесь на помощь придет PDFelement, передовое решение для работы с PDF-файлами. PDFelement позволяет быстро и эффективно конвертировать чаты с DeepSeek в PDF, сохраняя все важные данные и повышая удобство использования.
В этой статье
- DeepSeek для распознавания текста – Обзор
- Как извлечь текст из изображений при помощи DeepSeek
- Представляем PDFelement — для улучшения своего рабочего процесса по извлечению текста
- Почему вам стоит выбрать PDFelement для извлечения текста?
- Как извлечь текст из PDF
- Как извлечь текст из отсканированного в PDF
- DeepSeek или PDFelement — что лучше использовать для извлечения текста?
DeepSeek для распознавания текста – Обзор
DeepSeek использует ИИ для извлечения текста из изображений с высокой точностью. Независимо от того, работаете ли вы со отсканированными документами, фотографиями или снимками экрана, DeepSeek может быстро преобразовать текст на этих изображениях в форматы, доступные для редактирования и поиска.
Основные характеристики функции распознавания текста в DeepSeek:
- DeepSeek: преобразование изображения в текст: Извлечение текста из изображений за считанные секунды.
- Чтение изображений с помощью Deep Seek: Точно распознает текст из сложных макетов, рукописных заметок или изображений низкого качества.
- Эффективность: Экономит время за счет автоматизации извлечения текста с помощью распознавания на основе ИИ.
Используя возможности оптического распознавания символов DeepSeek, вы можете сэкономить время, сократить объем ручного труда и повысить производительность.
Как извлечь текст из изображений при помощи DeepSeek
Извлечение текста из изображений с помощью DeepSeek — это очень простой процесс. Вот пошаговое руководство которое поможет вам начать работу:
Шаг 1 Загрузите изображение
Начните с загрузки файла изображения, из которого необходимо извлечь текст. DeepSeek поддерживает множество форматов изображений, включая JPEG, PNG и BMP.
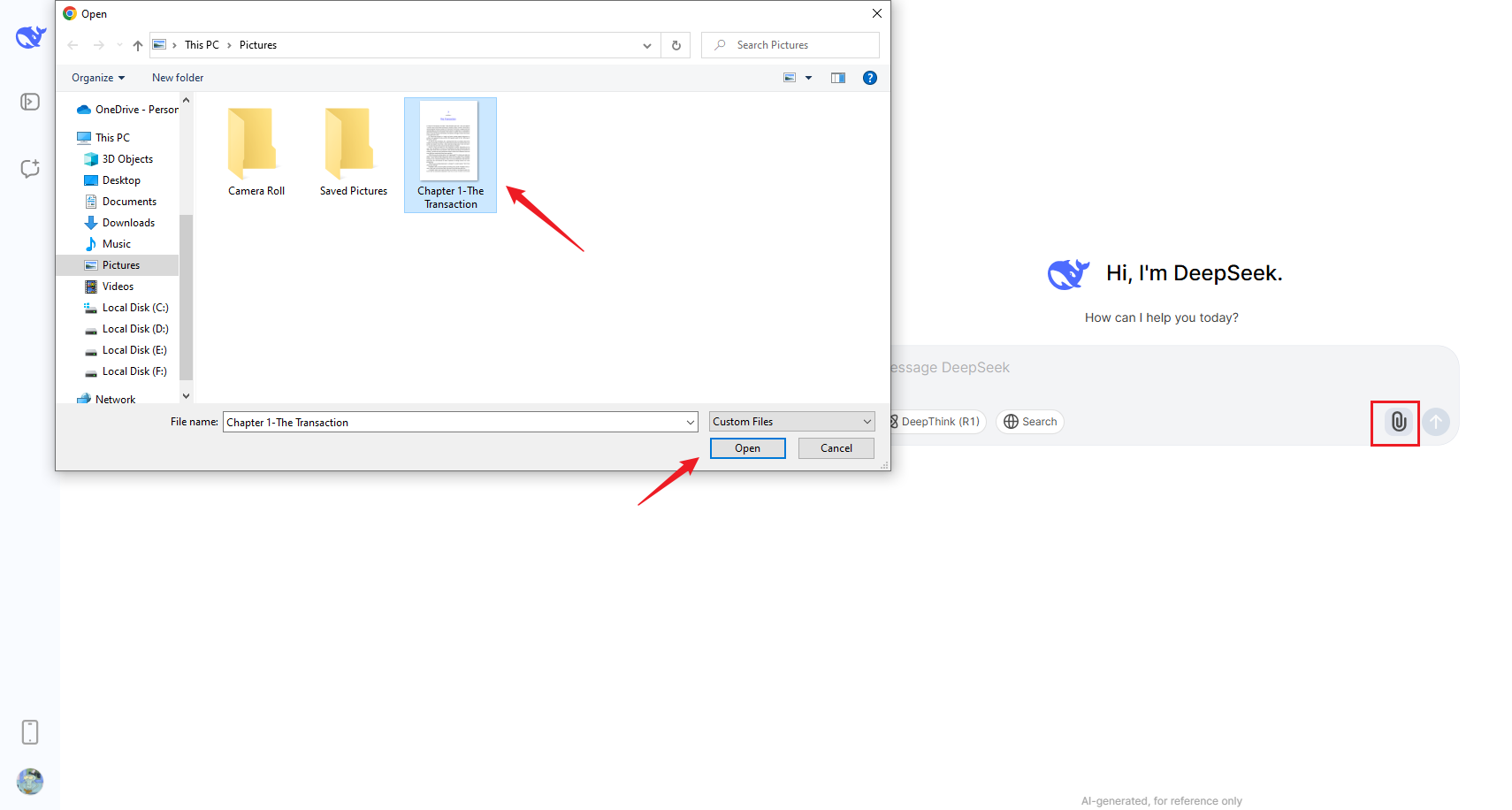
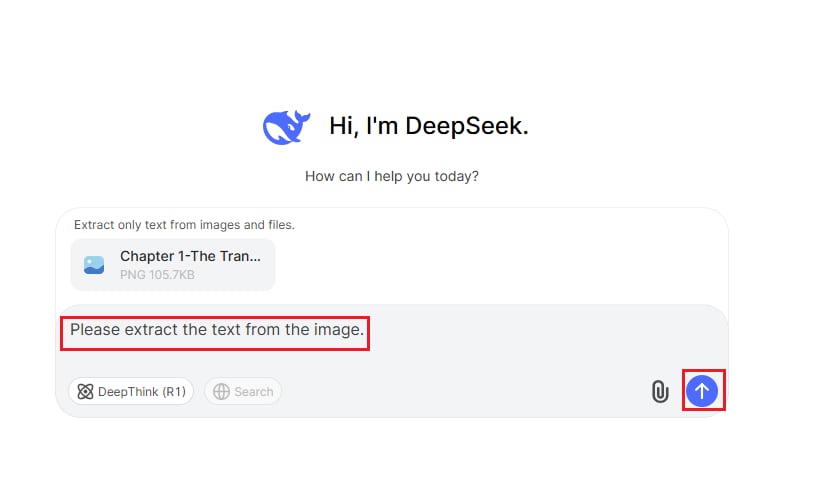
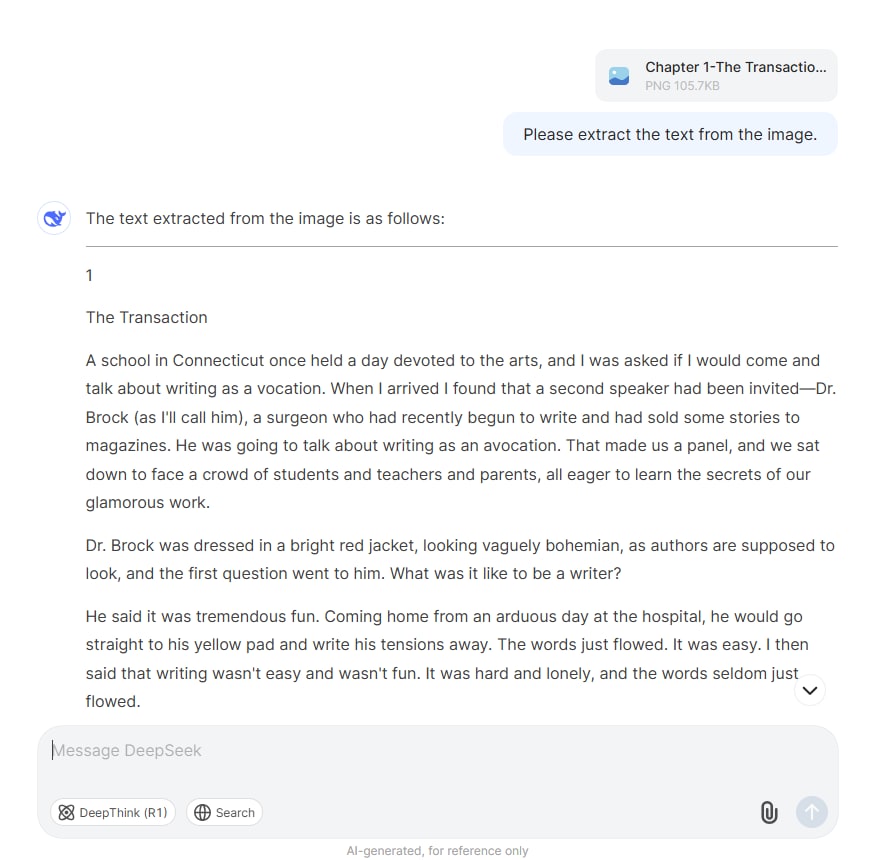
Шаг 2 Введите запрос и запустите процесс распознавания текста.
Введите запрос, например «Извлеките текст из изображения», а затем используйте ИИ DeepSeek для обработки изображения и извлечения текста.
Шаг 3 Предварительный просмотр и редактирование
Проверьте точность извлеченного текста и по необходимости внесите изменения.
Шаг 4 Экспорт и использование
Копируйте и используйте текст в документах, отчетах или в любом другом необходимом формате.
Представляем PDFelement — для улучшения своего рабочего процесса по извлечению текста
Хотя Deep Seek отлично справляется с преобразованием изображений в текст, PDFelement предлагает надежное решение для обработки извлеченного текста в документах. PDFelement предоставляет инструмент распознавания текста на базе ИИ для извлечения текста из изображений и отсканированных PDF-файлов, обеспечивая бесперебойное управление документами.
Основные возможности PDFelement:
- Распознавание отсканированных PDF-файлов: Точность извлеченного текста из отсканированных PDF-файлов и изображений.
- Редактирование PDF-файла: Легко редактировать текст, изображения и макеты.
- Аннотирование PDF: Возможность добавить комментарии, выделения и заметки.
- Конвертирование PDF-файла: Экспортируйте документы в Word, Excel и другие форматы.
При помощи PDFelement вы можете оптимизировать свой рабочий процесс и обрабатывать все документы на одной платформе.
Почему вам стоит выбрать PDFelement для извлечения текста?
PDFelement выделяется как мощный инструмент для извлечения текста и управления документами. И вот почему:
1. Точность:
Технология оптического распознавания текста PDFelement на основе ИИ обеспечивает точное извлечение текста даже из изображений низкого качества или сложных макетов.
2. Простота в использовании:
Удобный интерфейс позволяет легко извлекать текст, редактировать его и управлять им без сложного обучения
3. Универсальность:
PDFelement — это больше, чем просто инструмент для распознавания текста. Это универсальное решение для редактирования, аннотирования и преобразования документов.
4. Экономичность:
По сравнению с другими инструментами PDFelement предлагает расширенные функции по доступной цене, что делает его прекрасным выбором как для частных лиц, так и для предприятий.
Как извлечь текст из PDF
Далее мы расскажем, как извлечь текст из PDF-файла с помощью PDFelement.
Шаг 1 Добавьте файлы PDF
Скачайте и установите PDFelement. Далее откройте PDF-файлы, из которых вы хотите извлечь текст.
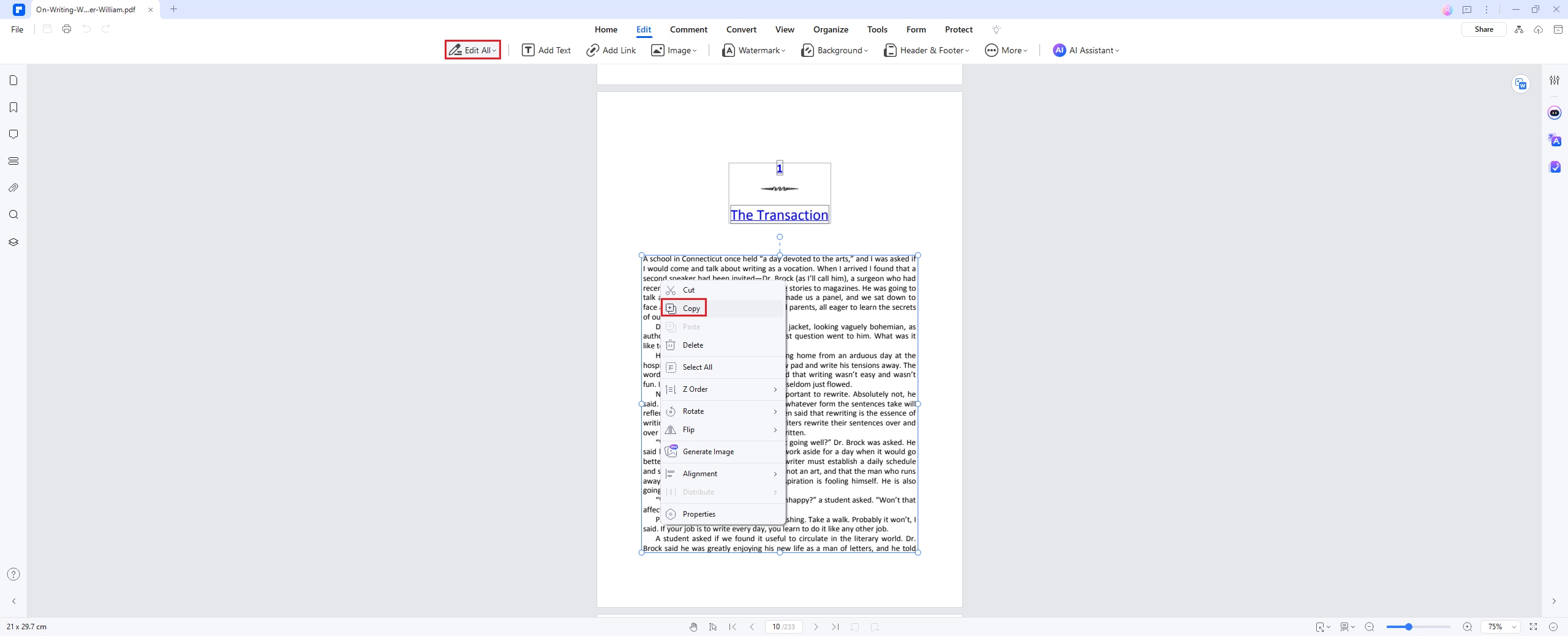
Шаг 2 Извлечение текста из PDF-файла
После открытия файла нажмите на вкладку «Редактировать» и выберите значок «Редактировать». Щелкните правой кнопкой мыши по тексту, выберите «Копировать» и извлеките нужный текст.
Как извлечь текст из отсканированного в PDF
Чтобы извлечь текст из изображений или из сканированного PDF-файла, выполните следующие действия в PDFelement.
Шаг 1 Откройте PDF-файл на с изображением.
После установки PDFelement откройте программу, чтобы выполнить распознавание теста в вашем PDF-файле. Нажмите «Открыть файлы», чтобы открыть отсканированный файл.
Шаг 2 Выполнение распознавания текста
После того, как вы откроете файл в программе, она определит, что это отсканированный документ, и предложит вам выполнить его распознавание. Нажмите кнопку «Выполнить распознавание» на верхней синей панели, затем выберите язык, на котором необходимо распознать документ и нажмите «ОК». По умолчанию будет установлен английский язык, но вы можете его легко изменить.
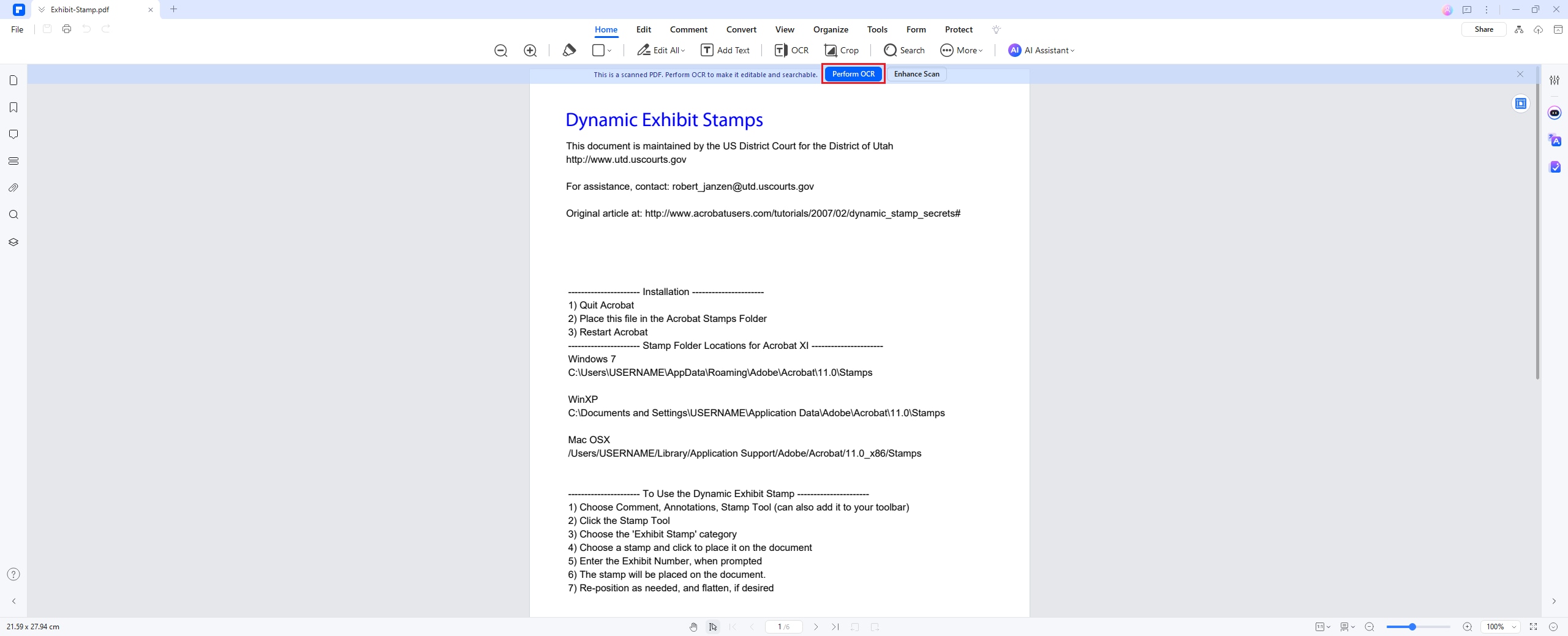
Шаг 3 Извлечение текста из изображения PDF
После завершения распознавания текста вы можете извлечь текст из вашего PDF. Для этого перейдите на вкладку «Изменить» и нажмите на кнопку-переключатель «Изменить» в правом верхнем углу. Выделите текст, который вам необходимо извлечь, затем щелкните правой кнопкой мыши и выберите «Копировать».
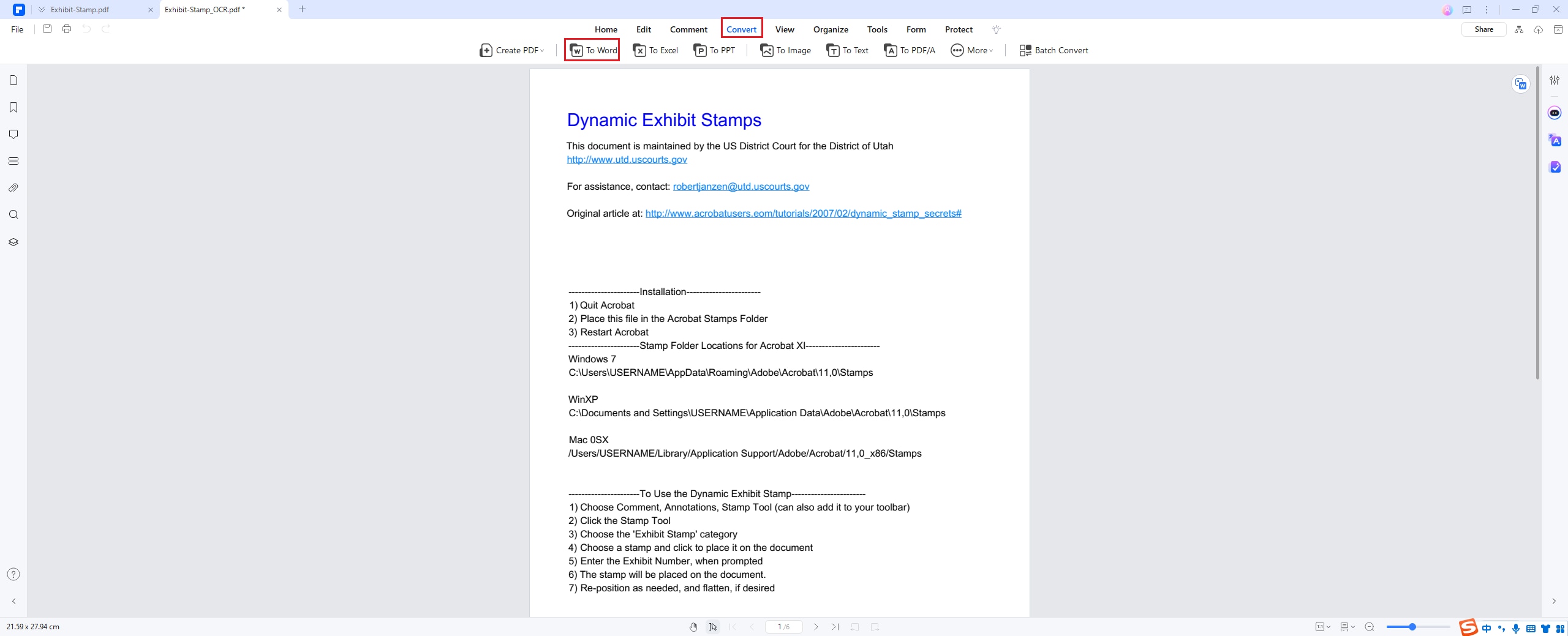
DeepSeek или PDFelement — что лучше использовать для извлечения текста?
И Deep Seek, и PDFelement предлагают мощные возможности извлечения текста, но они превосходны в разных сценариях:
- DeepSeek: Идеально подходит для быстрого и разового извлечения текста, особенно при работе с изображениями.
- PDFelement: Лучше всего подходит для комплексного управления документами, включая распознавание текста, редактирование и преобразование.
Если вы ищете инструмент, сочетающий извлечение текста с расширенной обработкой документов, то PDFelement — явный фаворит.
Заключение
DeepSeek упрощает извлечение текста из изображений с помощью распознавания текста на базе ИИ, что делает его ценным инструментом для быстрого преобразования текста. Однако PDFelement предлагает дополнительные функции, такие как извлечение текста из отсканированного документа, редактирование текста, аннотирование и преобразование форматов для комплексного решения по управлению документами.
Готовы упростить процесс извлечения текста? Попробуйте Wondershare PDFelement уже сегодня для бесперебойной работы с документами и повышения производительности.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ