представьте себе, работая с сотнями отсканированных страниц или PDF-файлами на основе изображений и понимая, что вы не можете скопировать или искать какой-либо текст внутри них. это расстраивает, когда вам просто нужно быстро извлекать информацию или создать автоматизированный рабочий процесс. Deepseek изменяет это, превращая отсканированные документы в машинно читаемый текст с использованием его передовой технологии оптического распознавания символов.
хотите ли вы обрабатывать длинные PDF, подключиться через API deepseek ocr или исследовать его ресурсы Github, это руководство поможет вам обо всем. вы также обнаружите более простую, безкодовую альтернативу ocr для мгновенной очистки PDF и многоязычного извлечения текста.
в этой статье
- быстрый ответ
- что такое глубокий поиск ocr?
- DeepSeek OCR API-как это называть
- Deepseek ocr на github-Clone
- использование deepseek ocr для PDF
- Оллама глубокий поиск ocr (идея первой местности)
- более быстрый путь для повседневных команд: PDFelement (без кода pdf ocr
- Deepseek ocr против pdfelement против классического ocr-когда что использовать
- пошаговые игровые тетради (готовые к копированию)
- известные соображения (точность, безопасность, доступность)
часть 1. быстрый ответ
Deepseek-ocr — это программное обеспечение с открытым исходным кодом, которое использует «оптическое сжатие» для обработки огромных документов со сверхдлинным контекстом. это лучше всего для разработчиков, которым нужна крупномасштабная экстракция, и доступно на Github с полными API-документами онлайн. Для большинства команд, нуждающихся в многоязычном ocr с простым интерфейсом, ocr PDFelement и функции улучшения сканирования более практичны. выберите deepseek для эффективности токенов и выберите PDFelement для повседневного извлечения и очистки текста PDF с помощью удобных для пользователя инструментов.
часть 2. что такое глубокий поиск ocr?
Эта система превращает документы в компактные визуальные токены и обеспечивает сверхэффективную обработку длинного контекста для AI. он сохраняет сложную структуру макета, снижает затраты на токены и выводит готовый к анализу текст. чтобы помочь языковым моделям обрабатывать более длинные документы в одном пропуске, он сжимает страницы в визуальной презентации. поддерживает многоязычные и смешанные документы в рабочих процессах исследований, предприятий и разработчиков. давайте рассмотрим некоторые ключевые возможности и преимущества, которые предлагает этот инструмент.

- оптический механизм сжатия: преобразует страницы в компактные визуальные жетоны, чтобы языковые модели обрабатывали гораздо более длинные контексты.
- Уменьшение токенов на 10 ×: сокращает количество токенов примерно в десять раз, сохраняя при этом сильное узнавание в различных макетах документов.
- высокопропускная обработка: обеспечивает высокую пропускную способность для многостраничных рабочих нагрузок с использованием оптимизированных стратегий плитки, дозирования и кэширования.
- динамические режимы/разрешение: адаптирует разрешение и представления для научных PDF файлов, счетов-фактур, таблиц, диаграмм и файлов с тяжелыми диаграммами.
- структурированные выходы: генерирует структурированное снижение цены или json для сохранения таблиц, списков, диаграмм и общей иерархии документов.
вы можете ознакомиться с полным обзором исследования и образцами кода в официальном сайте deepseek.репозитория Githubитехнические документы.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
часть 3. DeepSeek OCR API-как это называть
API deepseek ocr позволяет разработчикам интегрировать расширенную обработку документов в свои рабочие процессы. Он легко доступен разработчикам, знакомым с openai sdks, без необходимости понимания совершенно нового формата API благодаря совместимости с openai. пользователи могут отправлять отсканированные страницы, изображения или PDF и получать структурированный текстовый вывод с помощью этого API. Результаты готовы для рабочих процессов AI, баз знаний или исследовательских конвейеров.
Формат API и структура запросов
API использует стандартную структуру запросов http, совместимую с sdks в стиле openai. типичный запрос включает в себя:
- URL конечной точки: конечная точка API, куда вы отправляете запросы на обработку документов, например,https://api.deepseek.com/v1/ocr.
- заголовки: включите свой токен носителя и любые необходимые данные аутентификации для доступа.
- входной файл: предоставьте загруженное изображение, страницу PDF или общедоступный URL для обработки ocr.
- необязательные параметры: укажите язык, режим макета, разрешение или другие предпочтения для лучших результатов.
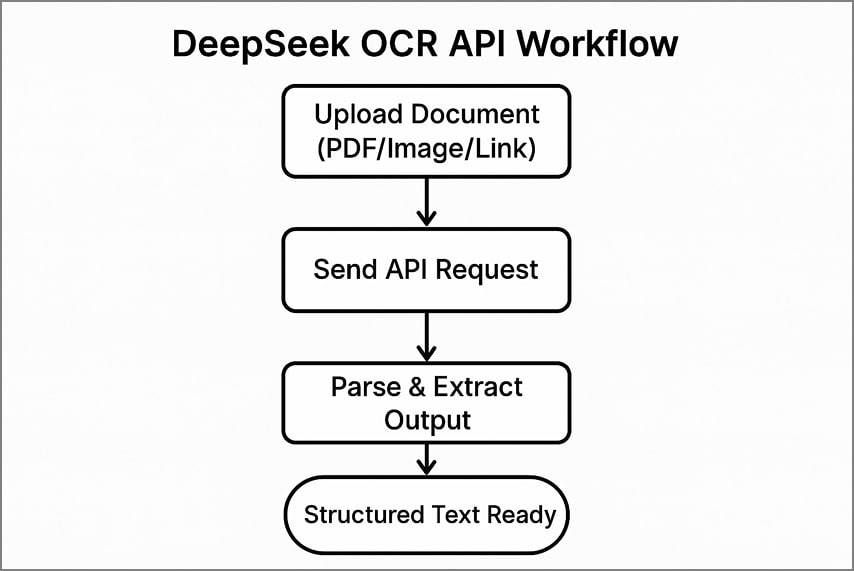
типичный рабочий процесс API
использование deepseek ocr для API включает в себя 3 четких шага обработки документов и извлечения структурированного текста.
- загрузите свой документ в API, отправив файл, страницу PDF или общедоступную ссылку.
- отправьте вызов API с заголовками аутентификации и выбранными параметрами обработки.
- анализируйте возвращаемый json или текст, чтобы точно извлечь распознанный контент, детали макета и визуальные жетоны.
ограничения тарифов, доступность и надежность
хотя API мощный, разработчики должны знать некоторые операционные соображения:
- доступность услуг: API показывает случайные колебания времени работы, поэтому планируйте потенциальные простои или замедление времени реагирования в производстве.
- Ограничения скорости: при работе с крупномасштабной обработкой вы можете достичь предела ежедневной или минутной скорости, тем самым используя повторные попытки в качестве способа времени возврата, чтобы сохранить непрерывность.
- обработка ошибок: всегда проверяйте ответы на наличие ошибок и изящно обрабатывайте исключения, чтобы избежать неудачных рабочих процессов в производстве.

часть 4. Deepseek ocr на github-Clone
мы рассмотрим, как вы можете установить deepseek ocr github локально, настроив среду python после клонирования репозитория.
доступ к репозиторию
Deepseek ocr доступен в качестве проекта с открытым исходным кодом на github, который предоставляет разработчикам полный доступ к его архитектуре и сценариям. репозиторий включает файлы конфигурации среды и документацию для развертывания или настройки. распределенный по разрешительной лицензии, он поддерживает как исследовательское, так и производственное использование. В проекте есть активное сообщество, которое часто способствует исправлению ошибок и улучшению рабочих процессов для локального развертывания.

локальная настройка (пошаговые команды)
для локальной установки deepseek ocr просто клонируйте репозиторий и подготовьте настройку python:
«git клон https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
Python-m venv venv
источник venv/bin/activate
Pip install-r requirements.txt "
инструмент совместим с версиями python 3.9 или более поздними. Вес модели можно загрузить автоматически при первом использовании или вручную по ссылкам в файле readme.
Требования к GPU и примечания к производительности
Deepseek ocr может работать на процессоре, хотя графический процессор, способный к cuda, настоятельно рекомендуется для обработки рабочих нагрузок ocr большого объема. в внутренних сравнениях существует возможность в 5–10 раз быстрее пропускной способности на многостраничных PDF или сложных макетах документов с использованием ускорения графического процессора. Для оптимальной производительности убедитесь, что ваши драйверы nvidia, версии CUDA и pytorch обновлены.
запуск выводов в PDF
После завершения настройки тестируйте образец pdf-файла, используя следующую команду:
"python infer.py --input sample.pdf --output output.json"
каждая страница отображается в виде изображения и обрабатывается через конвейер зрения vl2 для обнаружения текста и сохранения макета. структурированный вывод json или markdown интегрируется в локальные рабочие процессы llm на основе Rag или ollama.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
часть 5. использование deepseek ocr для PDF
давайте посмотрим, как разработчики обычно используют deepseekОКР PDFметоды извлечения точных текстовых и макетных данных из отсканированных или цифровых документов.
методы, используемые разработчиками сегодня
Для PDF сегодня существует два практических способа команд управлять Deepseek в зависимости от компромисса качества, стоимости и задержки.
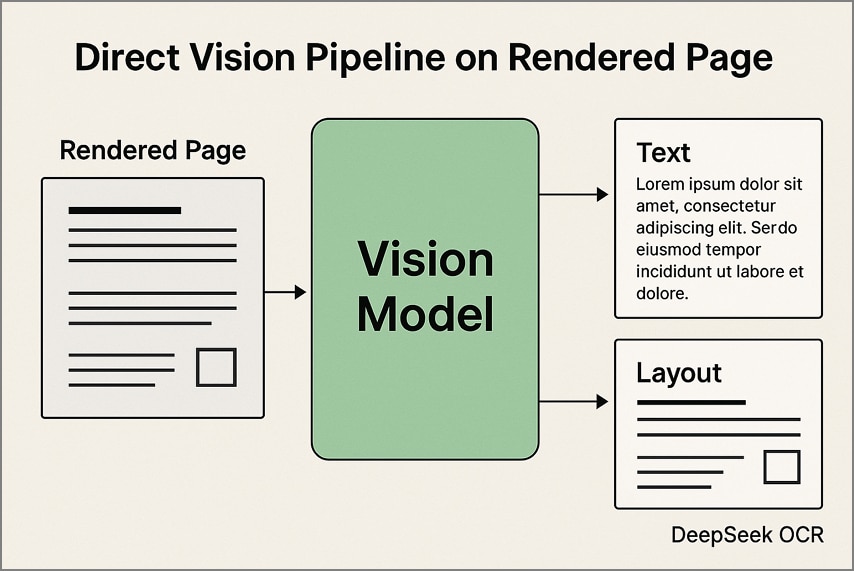
1. Трубопровод прямого зрения на отображаемых страницах
в этом подходе каждая страница PDF преобразуется в изображение с фиксированным разрешением, прежде чем его обрабатывать с помощью deepseek ocr. модель извлекает как текст, так и детали макета непосредственно из визуальных изображений, поддерживая таблицы, столбцы и диаграммы в их исходной структуре. этот метод особенно эффективен для отсканированных документов и визуально сложных макетов.
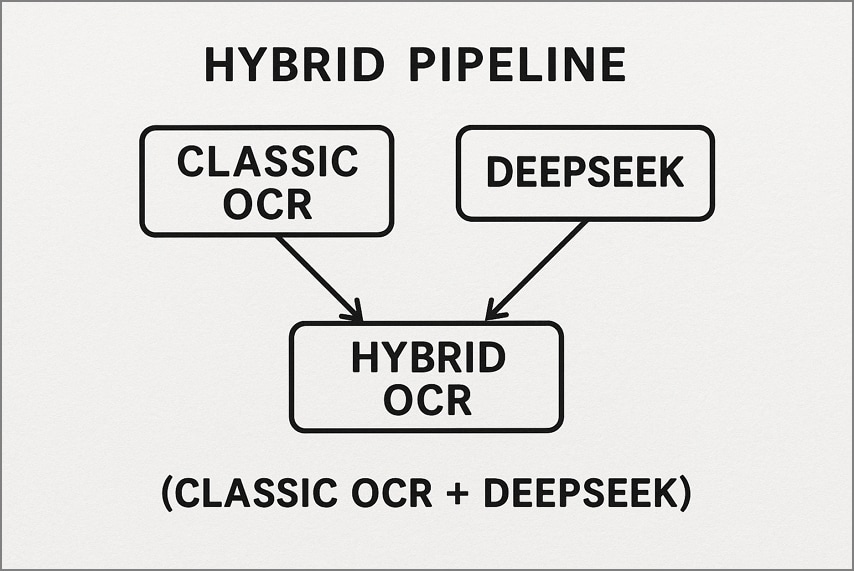
2. Гибридный трубопровод (классический ocr + DeepSeek)
здесь традиционный инструмент ocr, такой как tesseract, сначала обрабатывает простые высококачественные страницы для быстрого текстового вывода. только более сложные или шумные страницы передаются в deepseek ocr для более глубокой реконструкции макета и семантического понимания. этот рабочий процесс снижает затраты и задержку, при этом обеспечивая высокую точность при сложных документах.
краевые случаи
некоторые документы сложнее обрабатывать, чем стандартные текстовые страницы, поэтому важно осторожно обрабатывать краевые случаи для наилучшей точности ocr.
- Многоколончатые журналы/газеты: соблюдайте правильный порядок столбцов с помощью группировки строк после ocr, предпочитайте 300 dpi, плитка за столбцу для плотных страниц.
- штампы/водяные знаки/печати: маскируйте или отдельно накладывайте перед ocr, чтобы избежать ложного текста и неправильных слияний, а затем повторно вставьте.
- Skew/Rotation: сначала наклоните страницы, надежно обнаружите ориентацию, затем снова запустите ocr на поворотных страницах.
- сканирование с низким dpi: увеличение примерно в 1,5-2 раза и резкость, в противном случае предпочтите повторное сканирование с более высоким dpi.
- таблицы и формы: запустите детектор таблиц или шаг выравнивания заголовка, чтобы исправить разделенные ячейки, а затем проверить суммы и ключевые поля.
- Fonts/Math/Code: используйте плитки с более высоким разрешением для уравнений, кодовых блоков и очень маленьких шрифтов и сохраняйте моноинтервал с кодовыми ограждениями.
почему важна постобработка
постобработка — это простая очистка после извлечения текста, поэтому результат читается правильно. он исправляет смешанные столбцы, сломанные таблицы, беспорядочные заголовки и штампы, случайно читаемые как слова. если что-то выглядит не так, перезапустите эту страницу с более высоким качеством и проверьте суммы, даты и идентификаторы.
часть 6. Оллама глубокий поиск ocr (идея первой местности)
это легкая структура, которая запускает большие языковые модели исключительно на вашем компьютере с простым локальным API и cli. Ollama deepseek ocr позволяет вам обрабатывать сканированные документы и PDF-файлы сквозной на вашем компьютере, чтобы избежать зависимости облака и сохранить структуру в таких выходах, как снижение цены или json.
интеграция сообщества и примеры
В этом разделе мы рассмотрим общественные проекты, которые объединяют deepseek ocr с моделями олламы для обработки, извлечения и анализа местных документов.
- Streamlit OCR Studio: обтекаемая панель приборов принимает PDF и изображения и запускает deepseek ocr для структурированного текста. затем эта модель отвечает на вопросы пользователей по поводу извлеченного контента локально.
- Утилита извлечения markdown Ollama QA: от изображения к markdown используется для преобразования изображений страниц в чистую маркдаунную цену для использования ниже по течению. модель чата олламы обобщает документы и извлекает ключевые поля из PDF и отсканированных изображений.
- локальный анализатор Ollama API: служба папок для часов отображает новые файлы с помощью deepseek по мере их прибытия. он раскрывает локальную конечную точку олламы для поиска, вопросов
почему местная оркестрация помогает
после локального запуска OLLAMA с помощью deepseek ocr давайте рассмотрим некоторые ключевые преимущества этой настройки.
- храните документы на устройстве, чтобы соответствовать строгим политикам данных и уменьшить выявление нарушений во время аудита.
- работает полностью без Интернета в безопасных лабораториях и сетях с воздушным зазором для тестирования соответствия.
- избегайте сетевых задержек, локально контролируйте пакетирование и кэширование, а также стабилизируйте пропускную способность для больших PDF.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
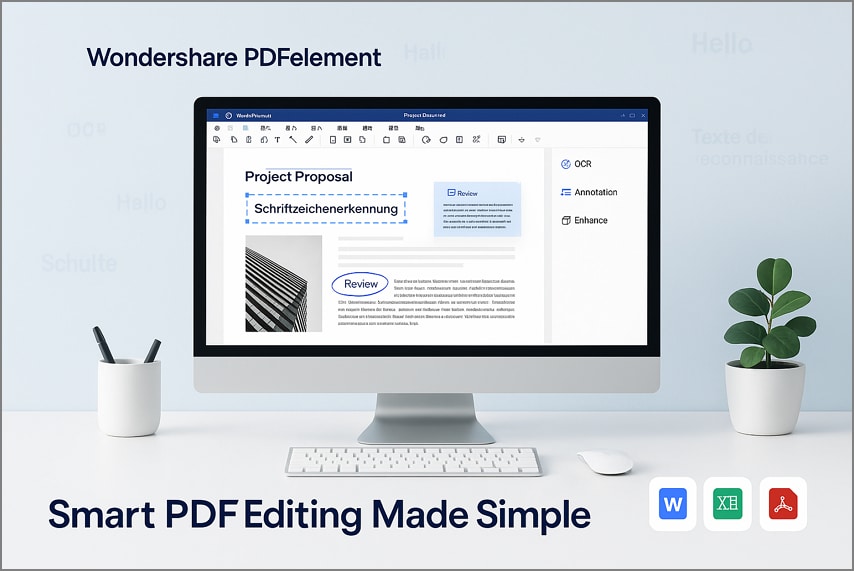
часть 7. более быстрый путь для повседневных команд: PDFelement (без кода pdf ocr
многим пользователям, не имеющим технического опыта, часто трудно извлекать текст из отсканированных PDF или документов на основе изображений. Помимо deepseek ocr, они ищут инструменты, которые предлагают простую обработку ocr, очистку документов и быстрое извлечение текста без технических знаний. Вот где PDFelement входит, что упрощает извлечение PDF без кодового ocr и помогает командам преобразовать документы в поисковые форматы за считанные секунды.
В отличие от других инструментов, пользователи также могут делать подчеркивания, добавлять водяной знак, вставлять фон и общаться с ИИ по поводу своих PDF-файлов. PDFelement предоставляет до 20 ГБ хранилища для сохранения данных прямо в этом инструменте и прямого обмена через социальные сети. Кроме того, чтобы сделать целевую область редактируемой, предлагается опция "OCR Area" для выбора определённых частей документа.
Полное руководство по безкодовому PDF OCR в PDFelement
После ознакомления с лучшим инструментом PDF OCR для пользователей без навыков программирования, следуйте пошаговой инструкции, чтобы быстро обрабатывать PDF-файлы как альтернативу DeepSeek OCR API:
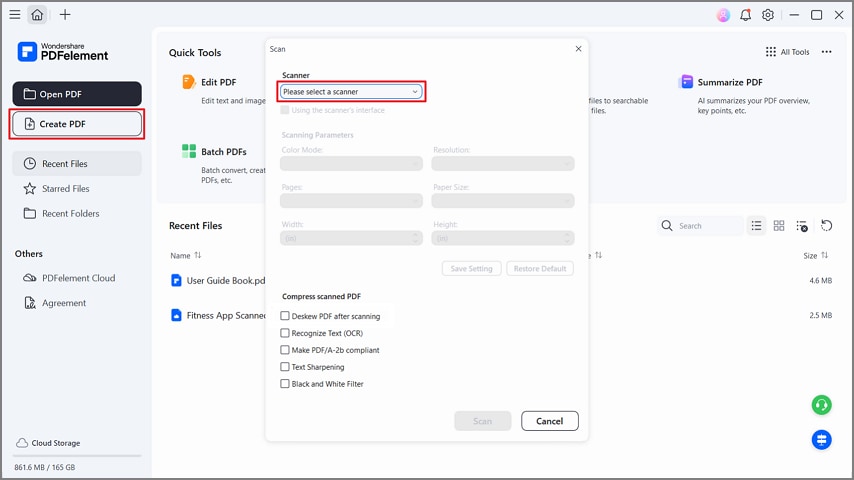
Шаг 1Создать PDF со сканера
После входа в инструмент нажмите кнопку "Создать PDF" и выберите опцию "Из сканера" в выпадающем меню. Затем выберите свой сканер и отметьте "Выровнять PDF после сканирования". Этот инструмент преобразует сканы в текст для поиска или редактирования с поддержкой настольного компьютера.
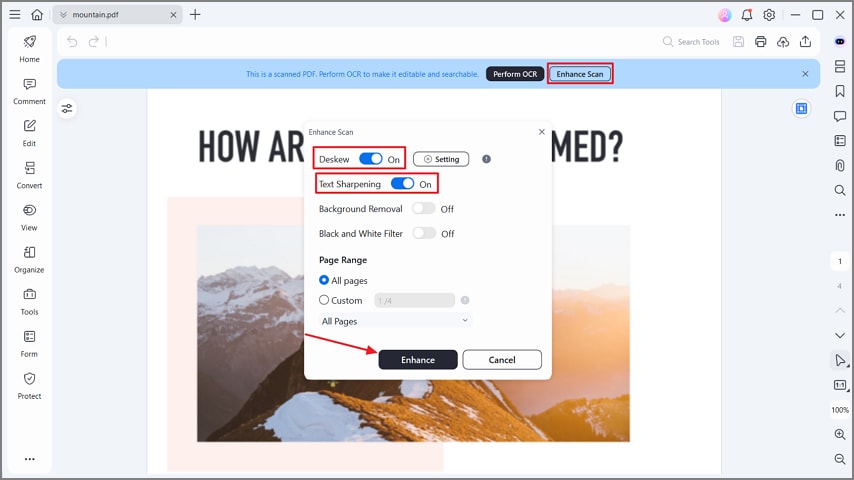
Шаг 2Улучшить ваш PDF
После создания отсканированного PDF-файла нажмите кнопку "Улучшить скан". Затем включите опции "Выровнять" и "Увеличение резкости текста" и нажмите "Улучшить" во всплывающем окне. Это повысит резкость текста, улучшая точность распознавания OCR на некачественных сканах.
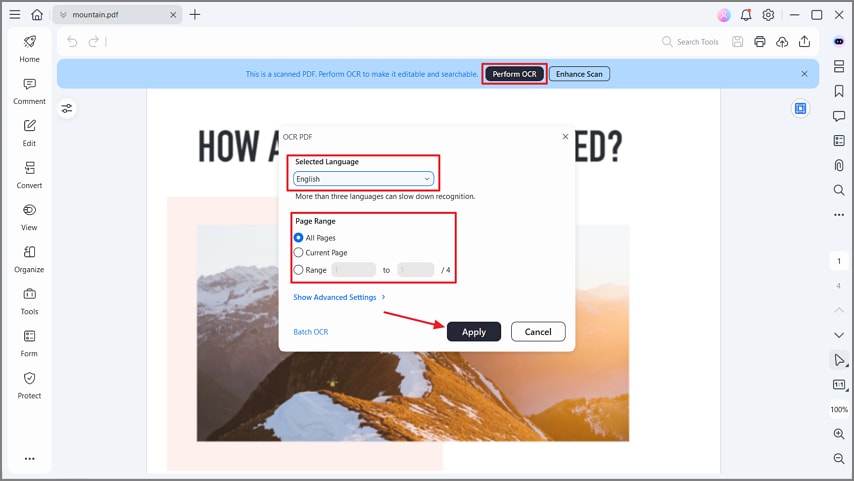
Шаг 3Выполнить OCR текста
Теперь нажмите кнопку "Выполнить OCR" и выберите нужный язык. Далее выберите конкретный "Диапазон страниц" и нажмите "Применить", чтобы начать процесс OCR. Это позволит извлечь текст из PDF и сделать его доступным для поиска и редактирования при просмотре или экспорте.
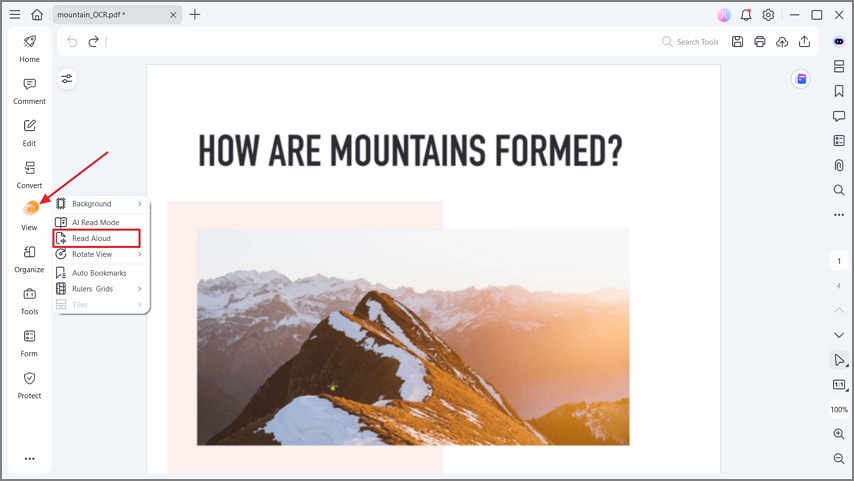
Шаг 4Озвучить PDF
После завершения OCR, выберите "Просмотр" в меню слева и нажмите "Озвучить", чтобы прослушать текст PDF-файла. Вы можете остановить или приостановить воспроизведение в любой момент. Эта функция позволяет корректировать PDF при прослушивании и выявлять ошибки.
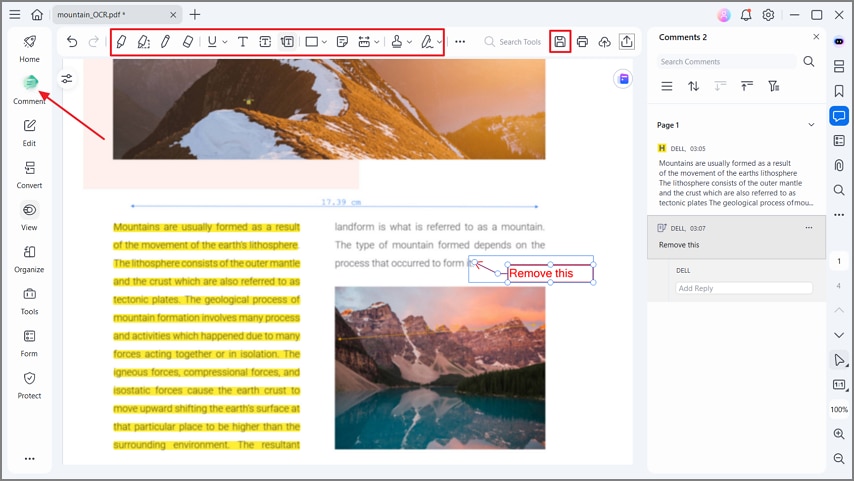
Шаг 5Аннотирование и экспорт PDF
Нажмите на кнопку "Комментарий" и используйте инструменты на панели для выделения текста и добавления комментариев в PDF. В заключение нажмите кнопку "Сохранить", чтобы экспортировать PDF-файл. Функция аннотирования также позволяет добавлять штампы, рисовать фигуры, прикреплять стикеры, подчеркивать или зачеркивать текст для более тщательного просмотра документа.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Часть 8. DeepSeek OCR vs PDFelement vs Классический OCR — Когда и что использовать
После изучения лучшей альтернативы DeepSeek OCR посмотрим, какие инструменты лучше подходят для различных сценариев использования и рабочих процессов с документами.
DeepSeek OCR
Лучший выбор для разработчиков, которым необходимы длинный контекст рассуждения, эффективный по токенам RAG, и ориентированный на структуру вывод в Markdown или JSON. Ожидайте работы по настройке, включая выбор размера GPU/VRAM, параметры пакетирования или разбивки, а также редкую тонкую настройку в сложных случаях.
Wondershare PDFelement
Надежный выбор для повседневной работы с документами, требующими многоязычного OCR, визуального улучшения сканов, аннотирования и просмотра. Экспорт в Word или Excel в один клик ускоряет передачу файлов, при этом команды избегают необходимости программирования или управления GPU.
Классические библиотеки OCR
Лучше всего работают с большим объёмом при простых и однородных макетах документов между партиями. Добавьте простые правила или таргетированный проход LLM только на трудных страницах, чтобы внедрить семантику без лишних затрат для всех документов. Ознакомьтесь с таблицей сравнения ниже, чтобы понять, как каждый инструмент подходит под разные сценарии и потребности пользователей.
| Инструмент | Фокус | Настройка | Длинный контекст | Обработка/Очистка | Многоязычный | Лучше всего для |
| DeepSeek OCR | Разработческие процессы, RAG | Технический | Умеренный | Ограниченный/Скриптовой | Умеренный | Разработчики, прототипирование, исследования, пайплайны RAG |
| PDFelement | Редактирование и обзор документов | Без кода | Высокий | Полный GUI набор | Высокий | Бизнес-команды, операции, соответствие, архивирование |
| Классический OCR | Пакетная обработка, простые документы | Технический | Средний | На скриптах | Умеренный | Пакетные задания, бэк-офис, простая структура |
Часть 9. Пошаговые инструкции (готовые к копированию)
Теперь, когда вы понимаете, как каждый инструмент подходит к разным рабочим процессам, перейдем к быстрым инструкциям. Следующие краткие инструкции показывают, как использовать DeepSeek OCR на GitHub и другие опции как для разработчиков, так и для обычных пользователей.
Разработчикам — попробуйте DeepSeek OCR API за 10 минут
- Шаг 1. Сгенерируйте ключ API в "Аккаунте" или "API Keys" и установите "DEEPSEEK_API_KEY".
- Шаг 2. Подготовьте POST-запрос к "/v1/chat/completions" с указанием модели, системной подсказки и схемы содержимого.
- Шаг 3. Отрендерите страницы PDF в PNG с фиксированным DPI и прикрепите base64 в "messages".
- Шаг 4. Запросите строгий JSON или Markdown и безопасно проанализируйте поле "content".
- Шаг 5. Проверьте поля, обработайте повторные попытки и сохраните данные в "Jobs" или "Storage".
Разработчикам — запуск с GitHub (локально)
- Шаг 1. Склонируйте репозиторий на машине с поддержкой CUDA и проверьте версии драйверов или инструментов.
- Шаг 2. Создайте venv, выполните "pip install -r requirements.txt", скачайте "weights" и установите "MODEL_PATH".
- Шаг 3. Преобразуйте PDF в изображения с постоянным DPI, выполните "infer.py --input pages --output out --format markdown".
- Шаг 4. Запишите задержку, VRAM и производительность, сравните точность с базовым OCR.
Пользователям — чистый OCR для PDF в PDFelement
- Шаг 1. Сначала нажмите "Создать PDF" и "Из сканера", чтобы отсканировать. Затем нажмите "Улучшить скан" и включите "Выровнять" и "Увеличение резкости текста".
- Шаг 2. Нажмите "Выполнить OCR", выберите "Язык", выберите "Редактируемый текст" или "Поисковый текст в изображении", затем нажмите "Применить".
- Шаг 3. Используйте "AI Read" или "Озвучить" для прослушивания, исправьте ошибки, замеченные во время воспроизведения.
- Шаг 4. Теперь нажмите "Комментарий" на левой панели для добавления "Выделения", "Комментариев" и "Стикеров" для рецензии.
- Шаг 5. В конце нажмите "Экспорт", чтобы сохранить PDF с поиском для передачи другим.
Часть 10. Важные моменты (точность, безопасность, доступность)
Перед полноценным внедрением в реальном производстве важно рассмотреть несколько практических факторов, влияющих на работу DeepSeek OCR API в реальных условиях.
- Точность: Результаты различаются в зависимости от макета страницы и качества скана, поэтому протестируйте производительность на собственном наборе документов. Используйте представительные документы, включайте таблицы и столбцы, отслеживайте ошибки, такие как разбиение и объединение.
- Безопасность и соответствие: Проверьте, как провайдер обрабатывает данные, хранение и срок хранения, избегайте передачи чувствительных файлов без оценки. Выполните редактирование перед загрузкой, ограничьте доступ и оформите одобрения для соответствия аудитам и внутренним политикам.
- Доступность и надёжность: Сервисы могут испытывать сбои или ограничения, поэтому добавьте повторные попытки, резерв и устойчивые локальные решения. Отслеживайте уровень ошибок и задержек, реагируйте на сбои и создайте чёткие инструкции для работы при инцидентах.
- Производительность и масштабирование: Относитесь к заявленной производительности как к ориентировочной, тестируйте на вашем оборудовании с фиксированным DPI. Измеряйте количество страниц в час, использование GPU/CPU и затраты, оптимизируйте партии и кэширование.
Часто задаваемые вопросы
-
Что такое DeepSeek OCR и почему важна "оптическая компрессия"?
DeepSeek OCR сжимает содержимое страницы в компактные визуальные токены, сохраняя структуру и уменьшая использование токенов для последующих моделей. Это важно, потому что охват большего количества документов в фиксированных ограничениях контекста и снижение затрат на инференс достигается при сохранении таблиц, списков и макета. -
Где находится репозиторий DeepSeek OCR на GitHub?
Официальный репозиторий содержит код, примеры и справочные материалы для локального запуска и адаптации пайплайнов. Клонируйте его, чтобы оценить результаты по сравнению с вашим базовым OCR, настроить промпты и экспортировать Markdown или JSON для интеграции. -
Существует ли DeepSeek OCR API и совместим ли он с OpenAI?
Существует API, принимающий запросы в стиле OpenAI с изображениями или отрендеренными страницами PDF. Можно запросить строгий JSON или Markdown, затем разобрать полученный ответ стандартными библиотеками и рабочими процессами. -
Как использовать DeepSeek OCR для PDF?
Преобразуйте каждую страницу PDF в изображение с постоянным DPI, выполните визуальное OCR, затем объедините страницы и обработайте таблицы и списки после. Альтернативно, сначала примените классический OCR для извлечения сырых текстов, затем используйте DeepSeek для восстановления структуры, семантики макета и генерации markdown. -
Могу ли я использовать его с Ollama локально?
Сообщество объединяет вывод DeepSeek с локальными моделями Ollama для вопросов и ответов, извлечения и валидации. Обычные сценарии включают панели Streamlit, автоматические процессоры для папок и легкие анализаторы документов без необходимости облачных сервисов. -
Мне просто нужно распознать текст в отсканированном PDF с поддержкой нескольких языков — что проще всего?
Используйте PDFelement для безкодового рабочего процесса, который надежно обрабатывает выравнивание, шумоподавление и многоязычный OCR. Улучшите скан, выберите нужный язык, проверьте с помощью Озвучивания или AI Read, аннотируйте и экспортируйте чистый, пригодный для поиска PDF.