Извлечение данных из файлов PDF необходимо во многих отраслях, включая финансы, здравоохранение и научные исследования. Поскольку организации все чаще используют PDF-файлы для обмена информацией, растет потребность в извлечении данных из PDF-файлов с помощью Python. Однако извлечение данных вручную может занять много времени и привести к ошибкам, что приведет к неэффективности и неточности обработки данных.
В этой статье
- Зачем извлекать данные из файлов PDF с помощью Python?
- Основные библиотеки для извлечения данных PDF на Python
- PDFelement: Упростите процесс извлечения данных из PDF-файлов
- Преимущества PDFelement по сравнению с ручным созданием скриптов на Python
- Как PDFelement работает с Python с полной интеграцией
- Пошаговое руководство по извлечению данных из файлов PDF с использованием Python и PDFelement
- Преимущества сочетания PDFelement с Python
Python приобрел огромную популярность как мощный инструмент для извлечения данных из файлов PDF. Благодаря обширным библиотекам и удобному синтаксису Python делает проще процесс извлечения данных из PDF-файлов Python. В этой статье мы покажем, как Python в сочетании с такими инструментами, как PDFelement, делает извлечение данных PDF в Python более простым и эффективным.
Зачем извлекать данные из файлов PDF с помощью Python?
Возможности Python по обработке файлов PDF обширны благодаря богатой экосистеме библиотек, специально разработанных для извлечения данных Python PDF. Эти библиотеки включают различные функции, отвечающие различным потребностям извлечения. Некоторые известные библиотеки:
PyPDF2
Эта библиотека позволяет выполнять базовое извлечение текста и обработку PDF-файлов, что делает ее отличной стартовой точкой для пользователей, желающих извлекать данные из PDF-файлов с помощью Python без сложного форматирования.
PyMuPDF (Fitz)
Эта программа хорошо и эффективно извлекает текст и аннотации. Он имеет более продвинутые функции, чем PyPDF2, и отлично справляется с извлечением структурированной информации, что делает его идеальным для документов, содержащих изображения или аннотации рядом с текстом.
PDFMiner
Данная библиотека предлагает расширенные функции для извлечения текста с сохранением структуры макета, что делает ее идеальной для сложных документов. С ней пользователи могут получить подробную информацию о расположении и форматировании текста, что имеет решающее значение при работе со сложными макетами.
Основные библиотеки для извлечения данных PDF на Python
PyPDF2
PyPDF2 — популярная библиотека, предоставляющая основные функции для чтения и обработки PDF-файлов. Она особенно полезна для пользователей, которые хотят извлекать данные из PDF-файла с помощью Python.
Что она может делать:
- Извлекать текст: Эта функция извлекает текст из отдельных страниц PDF-документа, обеспечивая легкий доступ к контенту.
- Объединение или разделение PDF-файлов: Объединяйте несколько PDF-документов в один файл или разделяйте большой PDF-файл на более мелкие части, которыми удобнее управлять.
Сценарии использования:
- Ситуации, когда вам нужно извлечь текст из простых PDF-файлов без сложной компоновки, например из отчетов или счетов-фактур.
- Объединение нескольких PDF-файлов в один документ полезно для упорядочивания связанных файлов.
PyMuPDF (Fitz)
Библиотека PyMuPDF, также известная как Fitz, — это мощный инструмент для извлечения текста и аннотаций из PDF-документов. Расширенные возможности делают ее предпочтительным выбором для пользователей, которым необходимо выполнять более сложные задачи по извлечению данных Python PDF.
Функционал:
- Эффективное извлечение текстов: Извлекает тексты, сохраняя макет, гарантируя, что на выходе сохранится исходное форматирование.
- Доступ к медиа и изображениям: Эта функция позволяет извлекать изображения и другие медиафайлы, встроенные в PDF-файл, что делает ее идеальной для визуально насыщенных документов.
Идеальные сценарии использования:
- Ситуации, когда вам необходимо извлечь подробную информацию вместе с изображениями или аннотациями, например, в научных работах или маркетинговых материалах.
- Для извлечения контента из насыщенных графикой PDF-файлов, где сохранение макета имеет решающее значение.
PDFMiner
PDFMiner — это продвинутая библиотека, специально разработанная для извлечения из PDF-файлов подробной информации, включая расположение и структуру текста. Она особенно полезна для пользователей, которым необходим точный контроль над тем, как данные извлекаются из их документов.
Возможности:
- Сохранение макетов: Возможность извлечения текста вместе с информацией о его макете делает ее идеальной для сложных документов, где структура имеет значение.
- Расширенный анализ текстов: Включает инструменты для анализа макета документов, что может иметь решающее значение, когда важно форматирование.
Сценарии использования:
- Ситуации, когда вам требуется точный контроль над тем, как извлекается текст в зависимости от его положения в документе, например, в юридических контрактах или технических руководствах.
- Для анализа макета документов, где форматирование имеет решающее значение, чтобы гарантировать, что сохранение заданной структуры извлекаемых данных.
Pandas для данных в таблицах
Интеграция pandas с другими библиотеками может оказаться полезной для извлечения структурированных табличных данных из PDF-файлов. Pandas позволяет эффективно управлять извлеченными данными и анализировать их, что делает его важным инструментом в вашем инструментарии Python для извлечения данных из PDF-файлов с помощью Python.
Преимущества:
- Манипулирование данными: Позволяет легко обрабатывать большие наборы данных, извлеченные из PDF-файлов, что упрощает дальнейший анализ и составление отчетов.
- Сложный анализ: Выполняйте сложный анализ структурированных данных с минимальными усилиями, используя мощные функции обработки данных pandas.
Используя библиотеки PyPDF2, PyMuPDF (Fitz), PDFMiner и pandas, пользователи могут эффективно извлекать данные из PDF-файлов с помощью Python, учитывая свои конкретные потребности. Независимо от того, извлекаете ли вы простой текст или сложные таблицы, надежная экосистема Python включает инструменты, необходимые для эффективного извлечения данных Python PDF.
PDFelement: Упростите процесс извлечения данных из PDF-файлов
PDFelement — это полнофункциональный редактор PDF-файлов с широким набором возможностей, упрощающих управление документами. Он включает удобные инструменты для удобного создания, редактирования, преобразования и извлечения данных из PDF-файлов.
Преимущества PDFelement по сравнению с ручным созданием скриптов на Python
Использование PDFelement дает ряд преимуществ по сравнению с традиционными методами ручного написания скриптов:
- Удобный интерфейс: PDFelement очень прост в использовании даже для тех, у кого нет опыта программирования. Такая доступность делает его отличным выбором для пользователей или команд, которые могут не обладать навыками программирования, но которым все равно нужны эффективные инструменты для извлечения данных из PDF-файлов с помощью Python.
- Технология оптического распознавания символов: Инструмент включает возможности оптического распознавания символов (OCR), которые позволяют пользователям эффективно извлекать текст из отсканированных PDF-файлов. Эта функция особенно полезна для оцифрованных физических документов.
- Параметры экспорта : Пользователи могут экспортировать извлеченные данные в структурированные форматы, включая Excel, CSV или Word. Библиотеки Python быстро обрабатывают эти форматы, обеспечивая беспроблемную интеграцию в существующие рабочие процессы.
Как PDFelement работает с Python с полной интеграцией
Вы можете извлекать данные с помощью удобного и интуитивно понятного интерфейса PDFelement, а затем обрабатывать их с помощью скриптов Python для дальнейшего анализа. Такое сочетание улучшает рабочий процесс, используя сильные стороны обоих инструментов: PDFelement упрощает процесс извлечения, а Python обеспечивает расширенные возможности обработки и анализа извлеченных данных.
Пошаговое руководство по извлечению данных из файлов PDF с использованием Python и PDFelement
Использование Python
Чтобы начать извлечение данных с помощью Python, необходимо установить необходимые библиотеки:
bash
установка pip pypdf2 pymupdf pdfminer.six pandas
Простой пример кода для извлечения данных в текстовой или табличной форме
Вот простой пример извлечения текста с помощью PyPDF2:
python
из PyPDF2 импортирование PdfReader
# Загрузите файл PDF
reader = PdfReader('example.pdf')
# Извлеките текст с каждой страницы
for page in reader.pages:
print(page.extract_text())
Ограничения извлечения только с помощью Python
Хотя использование библиотек Python для извлечения данных PDF обеспечивает гибкость, существуют и некоторые ограничения:
- Проблемы с отсканированными документами: Стандартные библиотеки не могут эффективно обрабатывать отсканированные документы без возможностей OCR. Это существенный недостаток при попытке извлечь данные из файла PDF с помощью Python, особенно если документы в основном состоят из изображений.
- Нарушение структуры данных: Если не принять специальных мер, извлечение таблиц может привести к нарушению форматирования или структуры. Это может усложнить дальнейший анализ, если важно сохранить исходный макет. Многие пользователи сталкиваются с трудностями при извлечении данных из PDF Python, особенно при работе со сложными таблицами, требующими точного форматирования.
Использование инструмента PDFelement для извлечения данных
Эффективное извлечение данных из PDF с помощью PDFelement:
Шаг 1
Откройте PDFelement и загрузите свой PDF-файл
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Шаг 2
Откройте вкладку «Форма» и выберите «Извлечь данные».
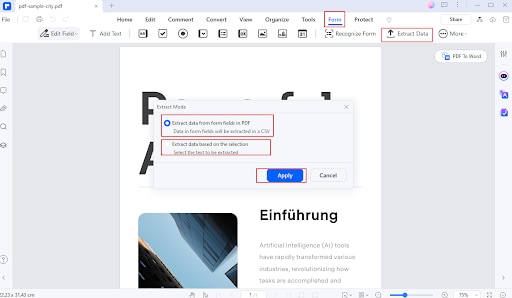
Шаг 3
Выберите желаемые параметры извлечения (например, поля формы или таблицы).
Преимущества сочетания PDFelement с Python
Интеграция PDFelement с Python дает ряд преимуществ пользователям, желающим улучшить извлечение данных PDF в Python:
- Улучшение эффективности: Сочетание интуитивно понятного интерфейса PDFelement с гибкостью Python повышает производительность, позволяя пользователям сосредоточиться не на логистике извлечения данных, а на анализе. Такая комбинация особенно полезна тем, кому регулярно приходится извлекать данные из PDF-файлов с помощью Python.
- Повышенная точность: PDFelement использует поддержку OCR для точного извлечения данных из отсканированных PDF-файлов, с чем стандартные библиотеки довольно часто не справляются. Данная функция имеет решающее значение для обеспечения того, чтобы важные данные не были потеряны в процессе извлечения.
- Экономия времени: Автоматизируйте повторяющиеся задачи, эффективно используя оба инструмента одновременно. Например, вы можете использовать PDFelement для обработки начальных извлечений, а затем применять скрипты Python для более глубокого анализа или составления отчетов. Такой подход помогает компаниям оптимизировать рабочие процессы и повысить общую эффективность управления многочисленными PDF-документами.
Это сочетание особенно идеально подходит для компаний, работающих с несколькими PDF-документами и сложными наборами данных, где эффективность и точность извлечения PDF-данных с помощью Python имеют первостепенное значение.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Заключение
В заключение следует отметить, что существуют разные варианты извлечения данных из PDF-файлов с помощью Python, включая такие библиотеки, как PyPDF2, PyMuPDF и PDFMiner. При этом PDFelement выделяется способностью оптимизировать процесс извлечения с помощью удобных для пользователя функций и мощных возможностей, что делает его отличным выбором для улучшения управления PDF-документами. Кроме того, DocuSign дает простой способ отказаться от подписания документов, который также можно интегрировать в ваш рабочий процесс, что еще больше повышает эффективность обработки данных PDF.