
PDFelement - мощный и простой PDF-редактор
Начните работу с самым простым способом управления PDF-файлами с помощью PDFelement !
PDF - это аббревиатура Portable Document Format, который считается лучшим форматом для обмена электронными документами. PDF-файлы присутствуют повсюду и являются жизненно важными в рабочих процессах каждой организации. Файлы PDF содержат все типы содержимого, включая таблицы. Банкирам необходимо извлекать информацию о клиентах из таблиц, учителям - извлекать оценки из таблиц для подготовки стенограмм, а бухгалтерам - данные из таблиц для создания счетов и квитанций.
Хотя существует несколько способов извлечения таблиц из PDF, Python зарекомендовал себя как отличный метод. Python - это интерактивный язык компьютерного программирования, используемый для разработки веб-сайтов и программного обеспечения. Однако он также предлагает платформу для чтения и извлечения таблиц из файлов PDF. Вы можете извлечь нужную таблицу из PDF с помощью Python, используя соответствующий фрагмент кода. В этой статье мы расскажем вам о самом простом способе извлечения таблицы из PDF с помощью Python.
Метод 1 : Используйте Tabular-Py Python Wrapper для извлечения таблиц из PDF
Tabular-py - это обертка tabular Java - java-библиотеки, которая позволяет пользователям читать содержимое таблицы, встроенной в PDF-документ. Он считывает содержимое таблицы и преобразует его в pandas DataFrame. С помощью tabula-py вы можете конвертировать PDF-файл в файлы CSV, TSV или JSON. Однако ваша система должна иметь Java8+ и Python 3.7+. Вы должны выполнить следующие команды для автоматической загрузки и установки необходимых зависимостей Java в вашей системе.
$ pip install tabula-py
$ pip install tabulate
Предположим, что путь сохранения PDF с целевой таблицей - /home/Ubuntu/data.pdf; вы можете запустить следующий код в терминале, чтобы извлечь таблицу из PDF и сохранить ее в формате CSV, TSV или JSON.
Импортные табуляторы
# начните с импорта библиотеки tabula
Импортные табуляторы
# чтение таблицы из файла pdf
dfs = tabula-read_pdf("/home/ubuntu/data.pdf",pages="all")
# преобразовать таблицу PDF в формат CSV
tabula.convert_into ("/home/ubuntu/data.pdf","output.csv","outpour_format="csv", pages="all")
Вы также можете извлечь и распечатать таблицу из терминала с помощью следующего кода.
из tabula import read_pdf
из tabulate import tabulate
# Эта команда считывает таблицу в ваш PDF-файл
df = read_pdf("/home/ubuntu/data.pdf",pages="all")
# Эта команда печатает ваш PDF-файл в терминале.
print(tabulate(df))
Команда read_pdf () считывает содержимое таблицы в ваш PDF-файл.
Команда tabulate () упорядочивает считанные данные в виде таблицы.
Советы и заметки
· Убедитесь, что Java присутствует в вашей системе.
· Постарайтесь иметь базовые знания Python, чтобы облегчить себе работу.
Метод 2 : Использование библиотеки Camelot-Py Python для извлечения таблицы из PDF
Camelot - еще одна полезная библиотека Python, которую можно использовать для извлечения таблиц из PDF-файлов. Красота Камелота заключается в уровне контроля, который он предлагает. Эта библиотека дает вам больше возможностей для настройки извлечения таблиц в соответствии с вашими потребностями. Кроме того, каждая таблица представляет собой Pandas DatFrame, который легко интегрировать в рабочие процессы ETL и анализа данных. С помощью библиотеки Camelot вы можете экспортировать свои таблицы в различные форматы файлов, включая JSON, Excel, HTML и Sqlite.
Чтобы установить библиотеку Camelot в вашей системе, выполните следующую команду.
$ pip install camelot-py
В отличие от tabula-py, Camelot использует таблицы и индексы для доступа к конкретной таблице в вашем PDF-файле. Сначала таблица считывается с помощью функции read_pdf (), а таблицы сохраняются в массиве таблиц. Массивы, очевидно, будут начинаться с таблиц [0], затем с таблиц [1] и так далее. Чтобы распечатать PDF в терминале, можно выполнить следующий код.
импортировать Камелот
# извлечь все таблицы из PDF-файла
abc = camelot.read_pdf("/home/ubuntu/data.pdf")
# выведите первую таблицу как Pandas DataFrame
print(abc[0].df)
Команда import Camelot импортирует библиотеку Camelot для использования в программе. Если библиотека Camelot не установлена, Python выведет сообщение об ошибке.
Команда Camelot.read_pdf () считывает содержимое вашего массива PDF и сохраняет его в массиве abc.
Команда print (abc[0].df) выводит на терминал первую таблицу в массиве, т.е. таблицу [0].
Советы и заметки
· Используйте функцию разбора для отбрасывания плохих таблиц на основе точности и пробелов.
· Если вы хотите извлечь таблицы с разных страниц и хотите изменить порядок извлечения, вы можете использовать команду order в функции парсинга.
· Постарайтесь ознакомиться с синтаксисом Python, чтобы свести к минимуму трудности преобразования.
[Bonus] PDFelement : Извлечение таблиц из PDF удобнее, чем с помощью Python
Хотя Python полезен для извлечения таблиц из PDF, он не предлагает удобства специализированного инструмента для извлечения данных из PDF. Python - это язык программирования, и понять и запомнить его синтаксис непросто. Если вы новичок в Python, вы можете прочитать первую строчку и разочароваться. Вам потребуются профессиональные знания для простой и точной навигации и извлечения таблиц из PDF. Даже если вы профессионал, процесс написания и выполнения кода для извлечения данных из таблиц является долгим и утомительным.
К счастью, PDFelement решает эту проблему, предоставляя удобную платформу для извлечения таблиц из PDF-файлов. Интерфейс элегантен и прост в использовании. Если вы новичок, то навигация и извлечение таблиц из PDF-файлов покажутся вам чрезвычайно простыми. Для извлечения таблиц из PDF-файлов с помощью этой программы вам не нужны знания кодирования или опыт. Кроме того, Wondershare PDFelement совместим с несколькими устройствами и операционными системами, включая Windows, Mac и iOS. Вам не нужно беспокоиться о добавлении библиотек, потому что эта программа является полной. Опять же, удивительная скорость обработки и доступность делают его удобным инструментом для всех пользователей, включая любителей.
Метод 1 : Извлечение таблиц с сохранением исходного формата
Иногда требуется извлечь таблицы из PDF без изменения исходного формата. Этот вариант полезен, когда вам нужна и таблица, и содержимое, вы хотите представить таблицу в точно таком же формате или не хотите менять макет таблицы. В PDFelement этот процесс выполняется быстро и просто, как показано ниже.
Шаг 1Сначала запустите PDFelement на своем устройстве и загрузите файл, из которого вы хотите извлечь таблицы. Вы также можете щелкнуть правой кнопкой мыши на PDF-файле и открыть его с помощью Wondershare PDFelement.
Шаг 2Когда PDF-файл загружен, перейдите на панель инструментов и нажмите на вкладку " Конвертировать ". из предложенных ниже вариантов выберите вариант " В Excel ".
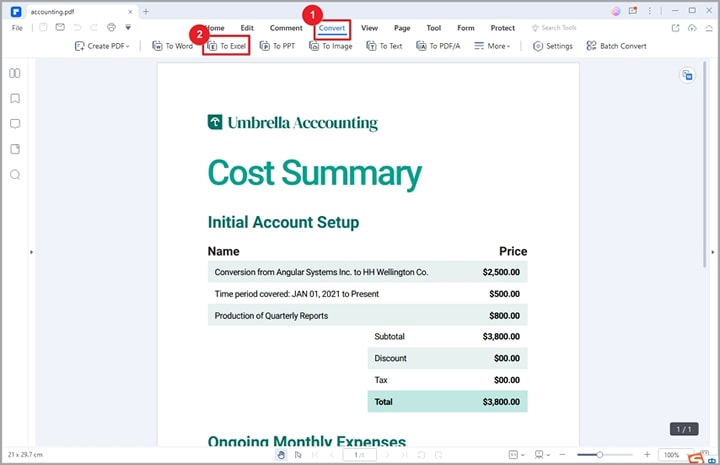
Шаг 3извлечение таблицы из pdf python альтернатива конвертация в excel Здесь выберите подходящую папку назначения и нажмите кнопку " Сохранить ". PDFelement немедленно преобразует ваш PDF-файл в файл Excel. Откройте файл Excel, чтобы проверить таблицу.
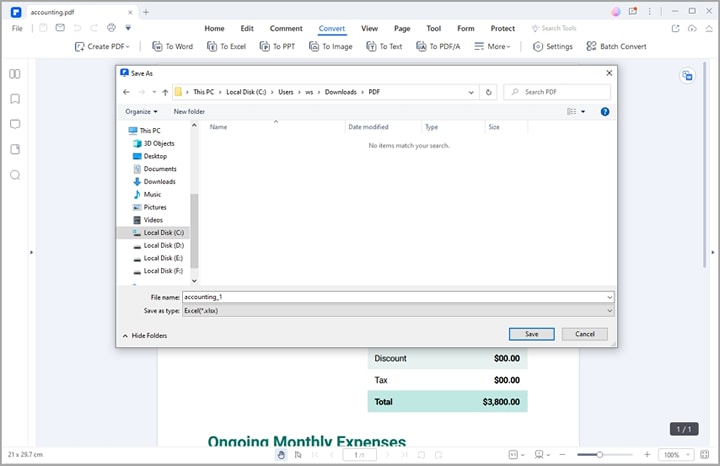
Советы и заметки
· Если вы обрабатываете несколько файлов, используйте пакетную обработку, чтобы сэкономить время и силы.
· Если у вас многостраничный файл и вам нужна только его часть, просто обрежьте ее перед конвертированием PDF в Excel.
Метод 2 : Извлечение только данных из PDF в CSV
В других случаях вам важен не формат таблицы, а ее содержание. В этом случае вы будете вынуждены извлечь только содержимое таблицы PDF. К счастью, PDFelement позволяет пользователям извлекать данные только из PDF в CSV. CSV - это формат обычного текста, который организует данные в табличной форме с использованием запятых.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Wondershare PDFelement - Редактор PDF-файлов позволяет извлекать данные из заполняемой PDF-формы. Однако форма PDF должна содержать поля формы, которые необходимо заполнить перед извлечением данных из таблицы PDF в CSV. Если поля формы не могут быть заполнены/распознаны, вам понадобится функция OCR в PDFelement, чтобы сделать их распознаваемыми/заполняемыми. Шаги проиллюстрированы ниже.
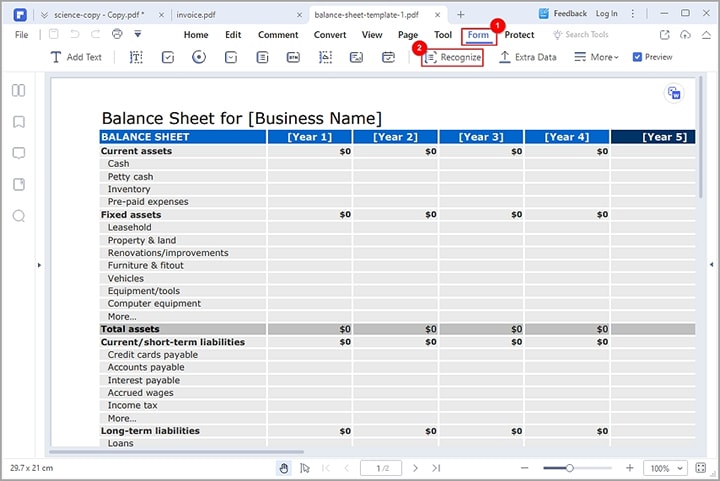
Шаг 1 Откройте PDF-файл с помощью PDFelement. Убедитесь, что на вашей версии PDFelement установлен плагин OCR.
Шаг 2 Перейдите в раздел " Форма " и нажмите на значок " Распознать " из нескольких вариантов, представленных под ним. PDFelementавтоматически сделает поля в ваших PDF-формах распознаваемыми.
Теперь, когда файл PDF распознан, необходимо извлечь данные таблицы из файла PDF следующим образом
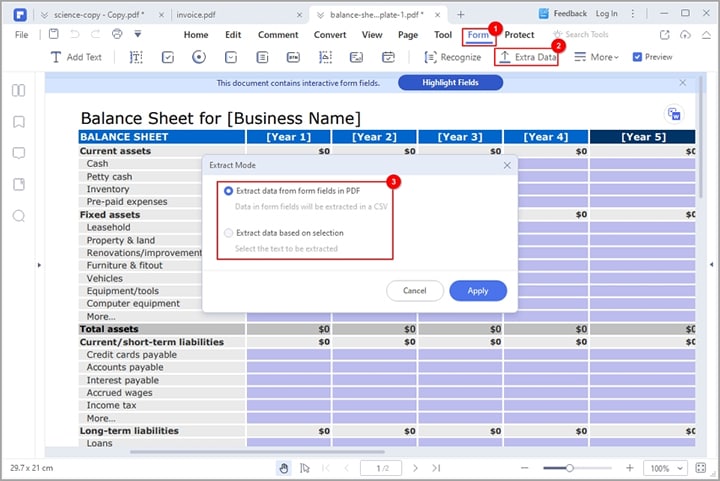
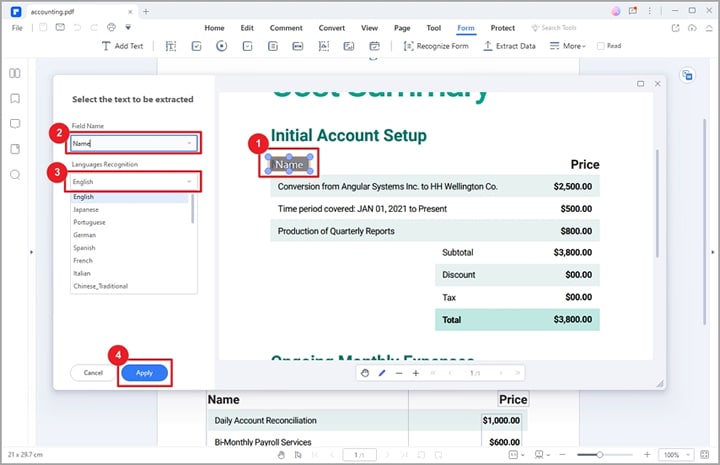
Шаг 1Перейдите на панель инструментов и выберите вкладку " Форма ". Из отображаемых опций выберите опцию " Извлечь данные ".
Шаг 2PDFelement выведет на экран диалоговое окно " Извлечь данные ". Здесь вы можете выбрать между "Извлечь данные из полей формы " и "Извлечь данные на основе выбора ". При выборе опции " Извлечь данные полей формы " поля вашей формы будут извлечены в файл CSV.
Если вы выбрали опцию " Извлечь данные на основе выбора ", вы должны выбрать каждое поле формы для извлечения с помощью курсора во всплывающем диалоговом окне. После этого введите название выбранных полей формы и выберите подходящий язык распознавания.
Шаг 3Выбрав все нужные поля формы, нажмите кнопку " Применить ". PDFelement немедленно извлечет данные только из PDF в CSV.
Советы и заметки
· Если вы хотите извлечь данные из незаполняемых полей, сначала убедитесь, что установлен плагин OCR для распознавания PDF.
· Используйте пакетную обработку, если у вас есть несколько PDF-файлов, данные из которых нужно извлечь из одного поля, или если вы хотите извлечь данные из PDF-формы с несколькими таблицами, содержащими разные данные.
· Функция "Извлечение данных на основе выбора" может применяться как к текстовым, так и к сканированным PDF-формам.
· Поскольку вам придется вручную выбирать каждое поле в форме, используйте опцию " Извлечь данные на основе выбора ", когда вам нужно только небольшое количество данных.
Извлечение таблиц из PDF с помощью Python требует знаний и опыта программирования. Однако PDFelement приближает извлечение таблиц PDF к вам благодаря интуитивно понятному и удобному интерфейсу. Процесс прост и удобен для каждого пользователя, включая новичков. Скачайте PDFelement сегодня и наслаждайтесь непревзойденным опытом извлечения таблиц из PDF.
