
PDFelement - мощный и простой PDF-редактор
Начните работу с самым простым способом управления PDF-файлами с помощью PDFelement!
С помощью оптического распознавания символов (OCR) можно преобразовать отсканированный документ в редактируемый и доступный для поиска текстовый файл. Она имеет различные применения и может быть частично реализована с помощью инструментов с открытым исходным кодом.
Получение открытого исходного кода является реальным вариантом для людей, желающих модифицировать OCR в соответствии со своими требованиями. Если вы хотите получить отличный инструмент OCR с открытым исходным кодом, мы поможем вам в этом. В этой статье вы узнаете о лучших инструментах для выполнения OCR в Интернете и о том, зачем они нужны людям. Давайте начнем!

Почему людям нужен инструмент OCR с открытым исходным кодом?
Некоторые из причин, по которым людям нужны инструменты OCR с открытым исходным кодом, следующие:
- Если вы хотите модифицировать OCR в соответствии с вашими требованиями, вам понадобится OCR с открытым исходным кодом.
- Поскольку OCR с открытым исходным кодом является более гибким и модифицируемым, чем инструменты OCR, он может лучше послужить вам, желающим добавить что-то инновационное в программу позже.
- Поскольку большинство программ OCR требуют дополнительной оплаты, вы не захотите покупать подписку, если программа нужна вам один или два раза в месяц. В этом сценарии вам может понадобиться программное обеспечение OCR с открытым исходным кодом.
Топ-4 лучших инструментов OCR с открытым исходным кодом в 2022 году
Теперь, когда вы знаете, почему вам требуется программное обеспечение OCR с открытым исходным кодом, вы, возможно, ищете лучший вариант. Вот что вы найдете в этом разделе. Здесь мы рассмотрели лучшие инструменты OCR PDF с открытым исходным кодом, которые включают:
1. Tesseract OCR
Tesseract от Hewlett-Packard широко считается лучшим механизмом OCR с открытым исходным кодом. Это программное обеспечение с открытым исходным кодом, выпускаемое под лицензией Apache и поддерживаемое Google с 2006 года. Механизм Tesseract OCR также является одним из наиболее точных и широко доступных решений с открытым исходным кодом. Последняя стабильная версия Tesseract, 4.1.1, основана на LSTM и может обрабатывать текст на 116 языках.
Поскольку Tesseract запускается из командной строки (CIL), он не имеет графического интерфейса пользователя (GUI). Благодаря усовершенствованному конвейеру предварительной обработки изображений и возможностям обучения нейронных сетей, он может получать новые знания. Кроме того, язык, качество изображения, подготовка данных, сегментация страниц и движок - все это играет роль в том, насколько точным будет результат.
Изображения могут быть предварительно обработаны с помощью библиотек OpenCV и ImageMagick для удаления шума, изменения размера, бинаризации, поворота, инвертирования, расширения и эрозии для получения более точных результатов с помощью этого инструмента OCR python с открытым исходным кодом.
Основные характеристики
- Он работает со многими языками и имеет обертки для многих из них, включая Java, Python, Ruby и Swift.
- Он совместим с другими программами для создания графических интерфейсов.
- Для загрузки изображений его движок обращается к библиотеке OCR с открытым исходным кодом, например, Leptonica.
- Она предоставляет людям множество возможностей для участия в жизни общества.
- Поддерживаемые языки: 116 языков, включая английский, испанский, хинди, польский, португальский и другие.
Преимущество
Поддерживает несколько языков программирования
Более высокая точность по сравнению с конкурентами
Неудобно
Трудно понять новичку
Чтобы выполнить распознавание PDF с использованием Tesseract OCR, выполните следующие действия:
Шаг 1 Сначала получите последнюю версию программы установки для Tesseract. Откройте командную строку и напишите pip install pytesseract, чтобы установить его.
Шаг 2 Теперь вам нужно прочитать изображение. Перейдите в Google Colab и напишите следующий код: Примечание: В cmd=r нужно указать путь к tesseract.exe на вашем компьютере. В файле cv2.imread необходимо указать имя изображения, которое вы загрузили в Colab.

Шаг 3 После считывания изображения пришло время преобразовать текст изображения в строку. Для этого необходимо добавить следующий фрагмент кода:

Шаг 4 Когда вы запустите код, вы получите на выходе текст изображения.
2.Azure OCR
API OCR в облаке Azure предоставляет программистам доступ к усовершенствованным алгоритмам чтения текста, которые позволяют получать структурированные данные из отсканированных фотографий. Инструменты OCR в Microsoft Azure позволяют извлекать печатные шрифты на нескольких языках, рукописный текст на многих языках, а также символы валют из картинок, цифр и многостраничных брошюр PDF.
Служба Azure Cognitive Service, Computer Vision, - это служба искусственного интеллекта (ИИ), которая оценивает неподвижные и движущиеся изображения на предмет релевантной информации. Среди многих функций, предлагаемых Azure OCR, - доступ к Azure Cognitive Services, API компьютерного зрения.
Поддерживаемые языки: 10+ языков, включая английский, японский, испанский и др.
Основные характеристики
- Доступны три облачных сервиса, и вы можете сравнить, насколько хорошо работают их алгоритмы OCR.
- Благодаря этому разработчики могут легко добавлять в свое программное обеспечение предварительно встроенные функции искусственного интеллекта.
- Благодаря переносимости контейнеров вы можете использовать те же богатые API, которые доступны в Azure.
- Можно извлекать информацию на различных языках и шрифтах, печатную и рукописную.
Преимущество
Скрипты на основе искусственного интеллекта для OCR
Надлежащая точность
Неудобно
Сложность для обычных пользователей
Чтобы выполнить OCR с помощью Azure OCR, выполните следующие действия:
Шаг 1 Зайдите на портал Azure Portal в предпочитаемом браузере. Чтобы получить доступ к Cognitive Services, перейдите в раздел AI + Machine Learning в подразделе All services главного меню.
Шаг 2 Выберите пункт Компьютерное зрение, Создать и настройте форму.
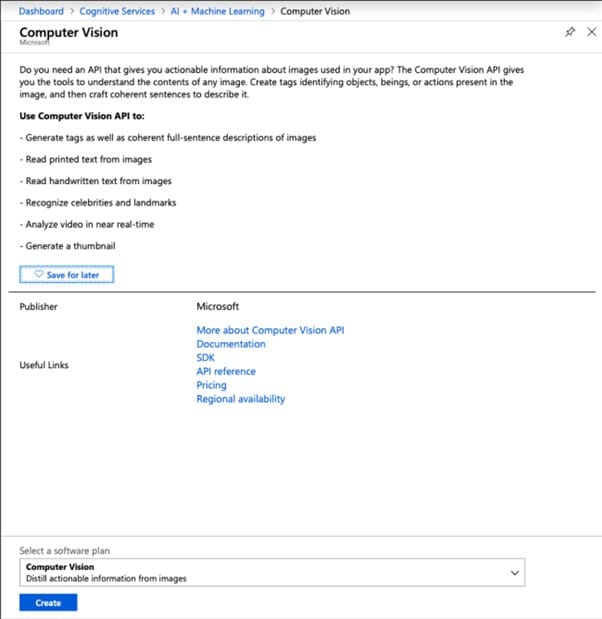
Шаг 3 Чтобы получить доступ к ресурсу OCR-Test, перейдите на приборную панель. Чтобы получить доступ к Ключам, выберите его в подменю Управление ресурсами.
Шаг 4 Будут видны два ключа; пожалуйста, скопируйте КЛЮЧ 1. Запишите следующий код в Google Colab.
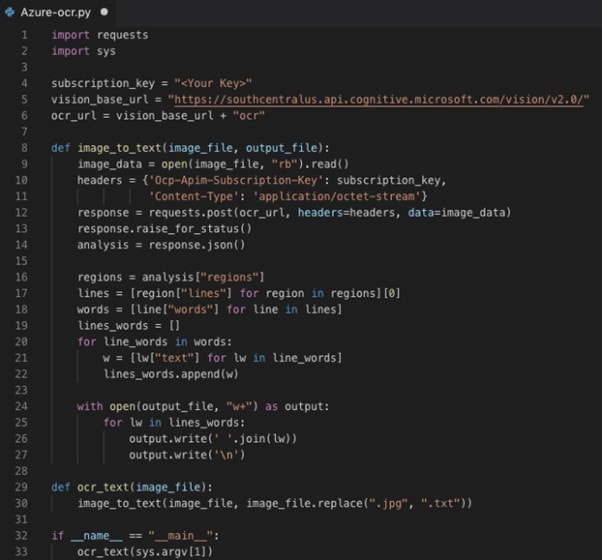
Шаг 5 Код при выполнении выдаст на консоль текстовый вывод, который будет представлять собой текст, извлеченный из картинки.
3.Abbyy OCR
При сканировании печатной или рукописной страницы в ABBYY OCR вы можете преобразовать ее в редактируемую копию документа. Он способен распознавать более 200 языков. С помощью этой программы можно конвертировать файлы PDF/изображений в текстовые форматы Word, Excel, PDF и т.д. с возможностью поиска. Распознанная информация преобразуется в XML (Extensible Markup Language). Этот ресурс представляет собой библиотеку для Java, .NET, iOS и Python.
Вы можете аннотировать и размечать документы, добавлять меры безопасности, такие как пароли и цифровые подписи, проверять документы с их помощью и многое другое. Функции приложения, позволяющие экономить время, облегчают совместную работу над проектами.
Поддерживаемые языки: Работает с 200 языками, включая русский, иврит, китайский, фарси и другие.
Основные характеристики
- Совместим с различными языками, включая японский, корейский, арабский, фарси, вьетнамский и тайский.
- Вы можете экспортировать документы в Word, Excel или PowerPoint.
- Поместите полученный архив в облачный сервис хранения данных, например Google Drive.
- Гладкий и интуитивно понятный пользовательский интерфейс позволяет легко вносить изменения и упорядочивать файлы.
Преимущество
Быстро и оперативно
Простота совместной работы
Неудобно
Довольно дорого
4.OCR Space
Если вам нужно превратить отсканированные фотографии или PDF-файлы в редактируемые документы, обратитесь к OCR Space. Это бесплатный инструмент распознавания текста на основе веб-технологий, который использует четыре различных механизма распознавания для извлечения текста из фотографий и PDF-файлов и отображения его в виде наложения. OCR Space - это простой в использовании онлайн-инструмент для преобразования отсканированных документов и PDF-файлов в редактируемый текст, который можно искать в цифровом формате.
Чтобы преобразовать документ в редактируемые файлы, вы можете либо загрузить файл, либо вставить URL-адрес. Программа может определить, когда изображение необходимо увеличить, и делает это автоматически.
Поддерживаемые языки: 20+ языков, включая английский, хинди, русский, испанский и др.
Основные характеристики
- Быстрое сканирование документов, включая сложные табличные схемы, такие как квитанции.
- Вы можете узнать, как ориентировано изображение, и автоматически повернуть его, если оно неправильно.
- Он поддерживает файлы с плохо контрастным текстом на сложном фоне.
- Максимально повысьте точность OCR, автоматически увеличивая файлы изображений или содержимое документов.
Преимущество
Полностью онлайн
Нет необходимости регистрироваться
Неудобно
Невозможно сгенерировать вывод в документе Word
Чтобы выполнить OCR с помощью OCR Space, выполните следующие действия:
Шаг 1 Перейдите в раздел OCR Space и выберите изображение или PDF с вашего компьютера, нажав кнопку Choose file. Изображения в форматах PNG, JPG и WebP поддерживаются OCR Space. Вы также можете ввести или вставить URL-адрес исходного файла изображения или PDF.
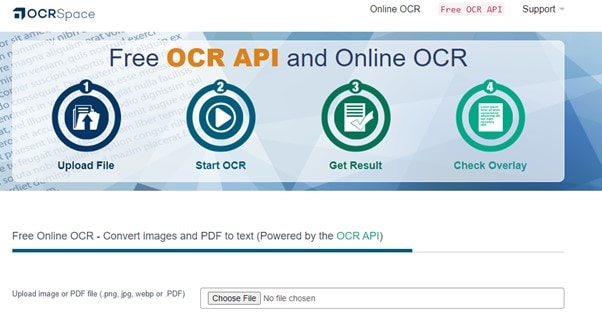
Шаг 2 Перейдите на вкладку Язык, чтобы установить язык в соответствии с текстом на изображении или PDF. У вас есть три варианта OCR Space, из которых вы можете выбрать, прежде чем начать процесс OCR. Выберите параметры в соответствии с вашими требованиями.
Шаг 3 После выбора движков рядом с опцией Select OCR Engine to use нажмите Start OCR, чтобы начать процесс сканирования.
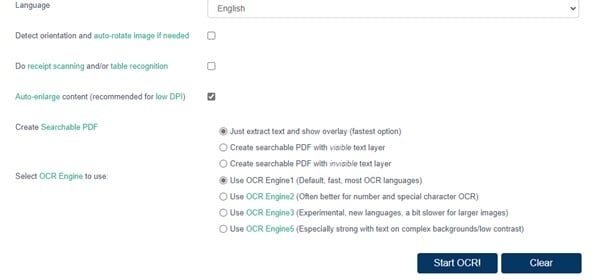
Шаг 4 После завершения процесса вы получите результат в текстовом виде рядом с изображением или PDF. Вы можете внести изменения, выбрать "Загрузить" или скопировать и вставить в текстовый редактор.
Лучший инструмент для распознавания PDF на Windows и iOS
Хотите найти лучший инструмент для PDF OCR для Windows и iOS устройств? Вы найдете его в этом разделе. Хотя вышеперечисленные инструменты являются лучшими для OCR с открытым исходным кодом, они не могут редактировать PDF-файлы в любой ситуации. Для этого вам потребуется качественное программное обеспечение, такое какWondershare PDFelement - Редактор PDF-файлов.
PDF подходит для работы со всеми требованиями к PDF. Пользователи могут легко редактировать отсканированные документы и пользоваться возможностью конвертировать распознанные OCR тексты в широко используемые форматы, включая Microsoft Word, Excel, HTML и PowerPoint. Настраиваемые текстовые поля, штампы и комментарии также являются частью этого инструмента. С помощью этого инструмента можно легко создавать контент в команде.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Основные характеристики
- Можно распознавать изображения и отсканированные документы с текстом внутри.
- Она позволяет пользователям извлекать текст из отсканированного PDF или изображения и использовать его для других целей, например, для копирования или поиска.
- Быстрое время обработки и богатые инструменты редактирования позволят вам создать PDF-файл, который будет выделяться на фоне других.
- Благодаря удобному интерфейсу даже новичок быстро освоится.
Что нам нравится
Удобный поиск текста в PDF
Можно преобразовать результат OCR в формат Word
Надлежащий инструмент настройки
Что нам не нравится
Вы не можете использовать некоторые функции редактирования бесплатно
Ценообразование: Бесплатно до $7,99
Поддерживаемые языки: Он поддерживает до 29 различных языков.
Чтобы выполнить PDF OCR с помощью PDFelement, выполните следующие действия:
Шаг 1 Установите PDFelement на свое устройство и запустите его. Нажмите на значок + или перетащите PDF, чтобы загрузить его.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
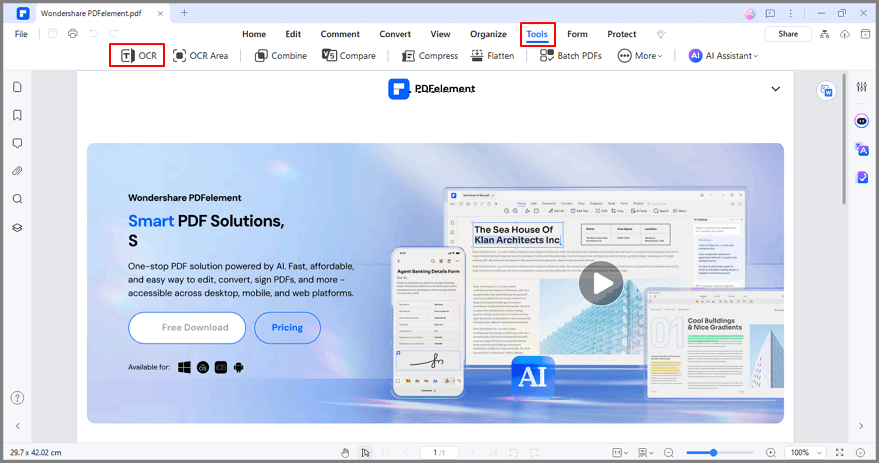
Шаг 2 Нажмите на Инструмент, а затем OCR, чтобы продолжить. Появится окно; выберите Editable Text (Редактируемый текст), а затем выберите язык, нажав на Choose Language (Выбрать язык). Затем нажмите OK, чтобы начать сканирование.
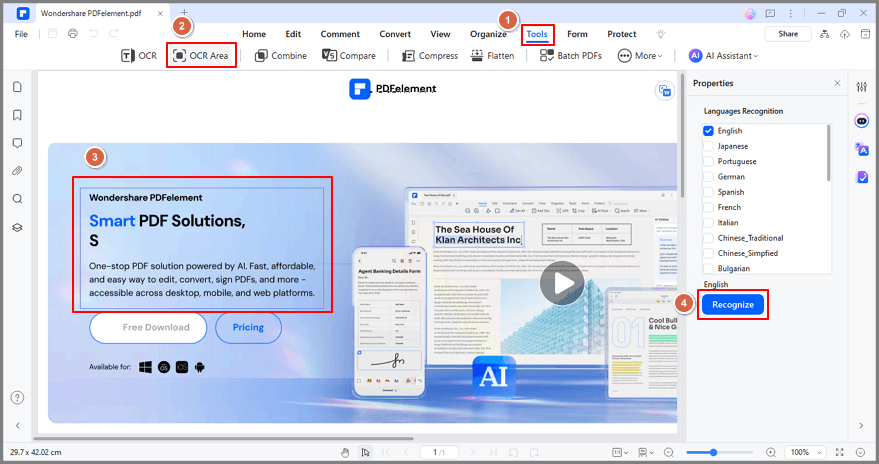
Шаг 3 После сканирования вы можете нажать кнопку Редактировать для редактирования текста PDF или В текст для экспорта редактируемого текста на компьютер.
Заключение
Инструменты OCR с открытым исходным кодом позволяют людям легко извлекать текст из изображений и PDF-файлов без загрузки программного обеспечения. Он также позволяет пользователю модифицировать инструмент в соответствии с его требованиями. Мы надеемся, что среди инструментов OCR с открытым исходным кодом, рассмотренных в этой статье, вы нашли подходящий. Кроме того, если вы хотите сделать PDF OCR на Windows или iOS устройстве, наша главная рекомендация - PDFelement.
