
Использование программного обеспечения для оптического распознавания символов (OCR) Linux является разумным шагом для людей и компаний, которым необходимо кодировать огромные объемы отсканированных документов или документов PDF.
Программное обеспечение упрощает жизнь, если вы хотите перейти на безбумажный документооборот. Это позволяет вам сделать ваши не редактируемые файлы "читаемыми" вашим устройством. Кроме того, это дает вам возможность быстро извлекать текст из ваших изображений.
Существует множество приложений такого типа. Эта статья для вас, если вы затрудняетесь с выбором лучшего средства для извлечения текста из изображений или PDF-файлов.
Список лучших программ для оптического распознавания символов
Найти программное обеспечение OCR для Linux может быть непросто. В отличие от Mac или Windows, эта операционная система имеет ограниченное количество пользователей, часто в технологической отрасли. Из-за их небольшого количества вы можете найти меньше приложений такого рода, разработанных для этой системы. Вот некоторые из них.
Tesseract
Если вы любите свободное программное обеспечение с открытым исходным кодом, Tesseract должен быть одним из ваших лучших вариантов. Несмотря на то, что вам не нужно ни копейки, чтобы установить это приложение на Linux, оно может дать вам отличные результаты. Это связано с тем, что Google разработал и предоставил движок для этого приложения. Это программное обеспечение может принести большую пользу возможностям и ресурсам технологического гиганта.

Tesseract — это мощный инструмент распознавания символов. Он может легко конвертировать разделы ваших книг, PDF-файлов, архивов и других типов текстов. Он также может обнаруживать символы в документах с крошечным размером шрифта и там, где текст трудно читать.
Tesseract может даже восстанавливать типы и размеры шрифтов в соответствии с оригиналом с минимальной погрешностью. Кроме того, он поддерживает более 100 глобальных языков, таких как китайский, испанский, арабский, а также региональные языки, такие как гуджарати, немецкий фрактур и себуано.
Чтобы использовать это программное обеспечение для распознавания PDF в Ubuntu, выберите файл, который вы хотите обработать.
Затем в командной строке tesseract введите информацию о файле, в том числе:
- Имя файла, который вы хотите обработать.
- Имя файла, который ваша система создаст для содержания извлеченного текста - он всегда будет сохранен в формате .txt, поэтому нет необходимости указывать расширение файла.
- Вы также можете использовать параметр --dpi, чтобы уведомить Tesseract о разрешении изображения в точках на дюйм (dpi). Если вы не укажете значение dpi, Tesseract определит его.
Например, если файл имеет формат img.png, команда может выглядеть следующим образом:
Выводом, по умолчанию, будет img.txt.
gImageReader
Другим популярным программным обеспечением OCR в Linux является gImageReader. Это приложение может выполнять множество функций, включая извлечение текста из нескольких файлов и проверку орфографии. Он также может выполнять постобработку машиночитаемого текста.
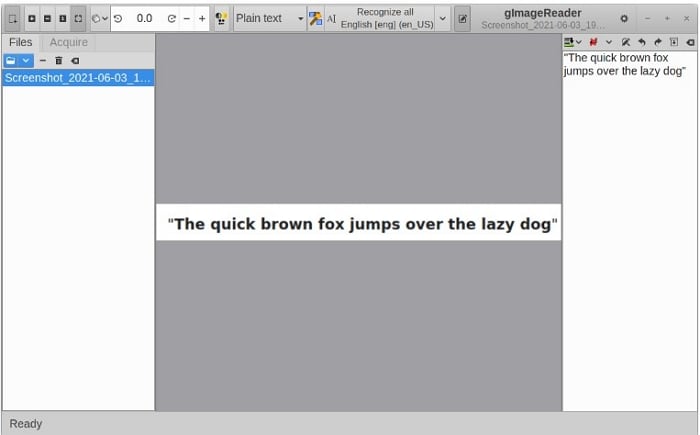
Позвольте gImageReader выполнить задачу OCR, выполнив следующие действия:
Шаг 1 Нажмите Добавить изображения в левом разделе под панелью инструментов и выберите изображение или PDF-файл, который вы хотите обработать.
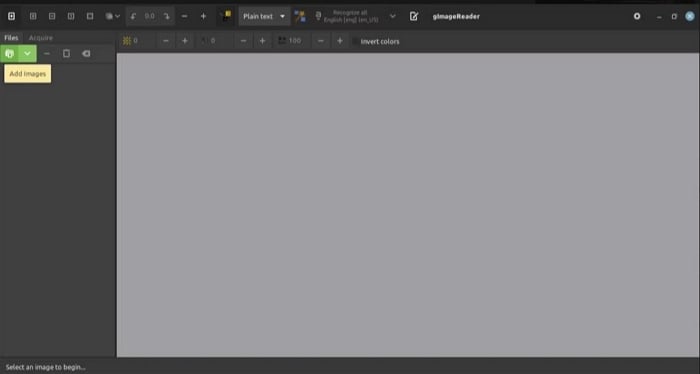
Шаг 2 Нажмите кнопку ОК, чтобы импортировать изображение или PDF-файл в программное обеспечение.
Шаг 3 У вас также есть возможность извлечь текст из файла, отображаемого на экране. Нажмите на выпадающий список рядом с "Добавить изображения" и выберите "Сделать снимок экрана". gImageReader сделает снимок экрана содержимого на экране.
Шаг 4 Загрузив изображение в gImageReader, нажмите на панель Toggle output (со значком блокнота), чтобы открыть панель вывода. Это позволит отобразить текст, извлеченный из изображений или PDF-файлов.
Шаг 5 Теперь у вас есть возможность определить текст в файле автоматически или вручную.
Шаг 6 Если вы выбрали автоматическую идентификацию, нажмите на кнопку Автоопределение макета, выделив все текстовые блоки в выбранном документе.
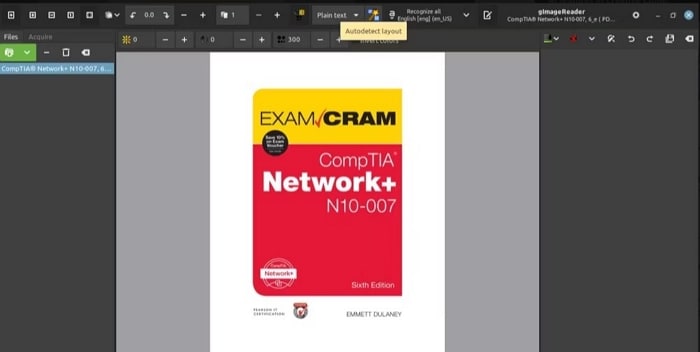
Шаг 7 Выберите Распознать выделение > Текущая страница, чтобы начать извлечение текста.
Шаг 8 Если вы предпочитаете выбирать текст вручную, наведите указатель мыши на текст, который нужно извлечь. Затем нажмите кнопку Распознать выбор, чтобы начать процесс.
OCRFeeder
Еще одним бесплатным OCR с открытым исходным кодом для Linux является OCRFeeder. По замыслу разработчиков, это приложение предназначено исключительно для пользователей Linux. В настоящее время это программное обеспечение поддерживается командой GNOME.
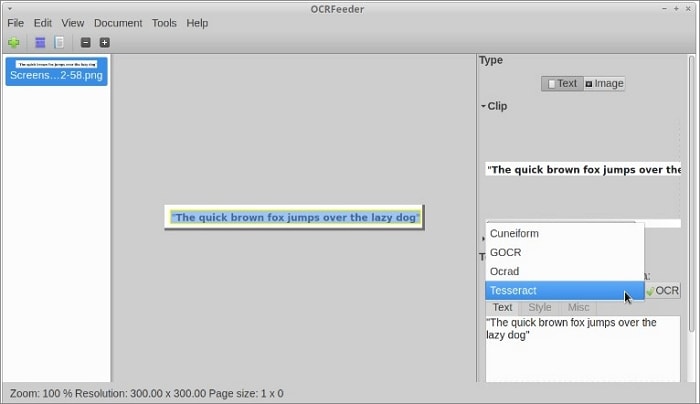
OCRFeeder ищет области содержимого и обводит их контуром, чтобы определить тип содержимого, будь то текст или изображение. Затем он обрабатывает текстовые области с помощью внутреннего модуля OCR.
Это приложение может использовать почти все движки OCR командной строки, включая Tesseract. Он также имеет функции автоопределения и автонастройки для всех известных бесплатных движков. Чтобы использовать OCRFeeder, выполните следующие действия:
Шаг 1 Откройте программу.
Шаг 2 Импортируйте изображение, из которого нужно извлечь текст. Можно также импортировать папку, содержащую файлы, которые вы собираетесь обработать.
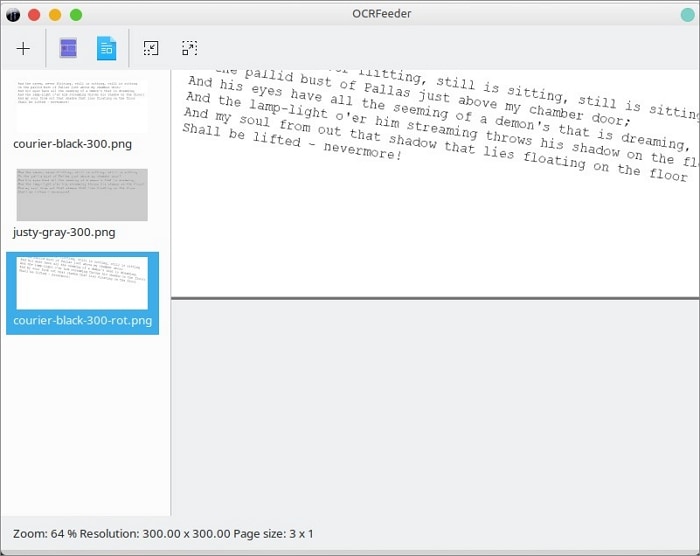
Шаг 3 Нажмите "Идентифицировать документ". После того как вы определили документ, вы можете вручную выбрать части, которые хотите извлечь.
Шаг 4 Перед экспортом документа выберите Edit > Edit Page, чтобы выбрать нужную страницу.
Шаг 5 Экспортируйте документ, выбрав Файл > Экспорт. Затем выберите нужный формат вывода, предпочтительно .txt.
FuzzyOCR
FuzzyOCR — это плагин для SpamAssassin, антиспам-платформы, которая проверяет различные файлы изображений, найденные в электронных письмах, чтобы определить, являются ли они спамом. Это приложение считывает изображения, прикрепленные к электронному письму. Затем он решает, являются ли они спамом или нет, на основе списка слов.

После того, как это программное обеспечение OCR установлено и настроено, оно может выполнять обнаружение изображений. Узнайте, как заставить это приложение работать:
Шаг 1 После загрузки распакуйте FuzzyOCR и переместите все файлы FuzzyOCR* и каталог FuzzyOCR.
Шаг 2 Настройте его так, чтобы он работал с помощью SpamAssassin, открыв файл с именем /etc/mail/spamassassin/FuzzyOCR.cf, затем внесите некоторые изменения:

Шаг 3 После того, как FuzzyOCR настроен, вы можете передавать каждое электронное письмо в SpamAssassin, чтобы увидеть, правильно ли плагин связан с программным обеспечением. Вот пример:
SpamAssassin теперь может распознавать спам с изображениями с помощью FuzzyOCR
Преимущества и ограничения распознавания символов в Linux
Любое программное обеспечение для распознавания символов в Linux имеет множество преимуществ. Благодаря развитию технологий эти приложения становятся все более и более надежными. Они незаменимы для людей и предприятий, которым необходимо быстрое и точное извлечение текста для безбумажной жизни.
Преимущества
Более высокая производительность - Вместо того, чтобы кодировать себя или делегировать это кому-то другому, вы можете запустить это программное обеспечение и позволить ему делать свое дело. Вы можете начать конвертировать текст, одновременно выполняя свою обычную работу.
Более низкая стоимость - Эта технология дешевле, чем платить кому-то за ввод огромного куска текстовых данных вручную. Чтобы сделать текст и изображения PDF машиночитаемыми, требуется меньше энергии и ресурсов.
Высокая точность - Эти приложения позволяют считывать собранную информацию. Планшетные сканеры и новейшие цифровые камеры позволяют создавать изображения с высоким разрешением, что позволяет этим приложениям обнаруживать текст.
Увеличенное пространство для хранения - Хранение отсканированных файлов изображений, особенно с высоким разрешением, требует значительного места на жестком диске. Превращение их в машинно-редактируемые документы даст вашему диску достаточно места для хранения других, более важных файлов.
Высочайшая безопасность данных - Утерянные или отсканированные бумажные документы могут стать кошмаром для безопасности. Неправильное обращение с файлом может привести к его подделке. Вы можете хранить документы без подписей и печатей, если вы можете преобразовать и сохранить их в редактируемом файле.
Ограничения
Трудности с распознаванием рукописного текста - Эти приложения эффективно работают с печатным текстом, но имеют проблемы с чтением рукописного текста. Как и в случае с людьми, некоторые почерки трудно читать.
Для установки PDF-файлов и других файлов может потребоваться несколько человек с продвинутыми техническими навыками - Вам может понадобиться несколько человек с продвинутыми техническими навыками. В отличие от Windows или Mac, лишь небольшая часть людей знает, как использовать эту операционную систему.
По-прежнему требует тонны редактирования - Хотя современное программное обеспечение OCR обладает высокой точностью, оно по-прежнему подвержено ошибкам. Вам все равно нужно тщательно проверять документы и вручную исправлять их, чтобы убедиться, что в них нет ошибок.
Точность распознавания зависит от качества изображения.
Лучший инструмент OCR для Windows, Mac и iOS
Приложения для распознавания символов доступны не только пользователям Linux. Пользователи Windows и Mac также могут выбирать из широкого спектра программного обеспечения для извлечения текста. Среди доступного программного обеспечения PDFelement является вашим разумным выбором благодаря своим передовым функциям.
Wondershare PDFelement - Редактор PDF-файлов имеет полный набор функций, которые делают извлечение текста удобным для пользователя. Программное обеспечение точно выполнит свою задачу, загрузив PDF или другие форматы изображений.
Помимо OCR, он имеет множество функций, которые могут упростить вашу работу. Сделав текст редактируемым, вы можете внести изменения и преобразовать файлы в PDF, Word, Excel и PowerPoint. Вы можете сделать его электронной книгой, экспортировав его в формат EPUB, или веб-страницей, сделав его HTML-файлом.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Вот шаги, как установить это программное обеспечение и использовать его в качестве инструмента OCR в Windows:
Шаг 1 Загрузите и установите PDFelement с его веб-сайта.
Шаг 2 Откройте PDF-файл и нажмите OCR на дополнительной кнопке навигации, чтобы использовать функцию OCR. Появится всплывающее окно с вопросом, хотите ли вы загрузить дополнительную функцию. Нажмите Загрузить и завершите установку.
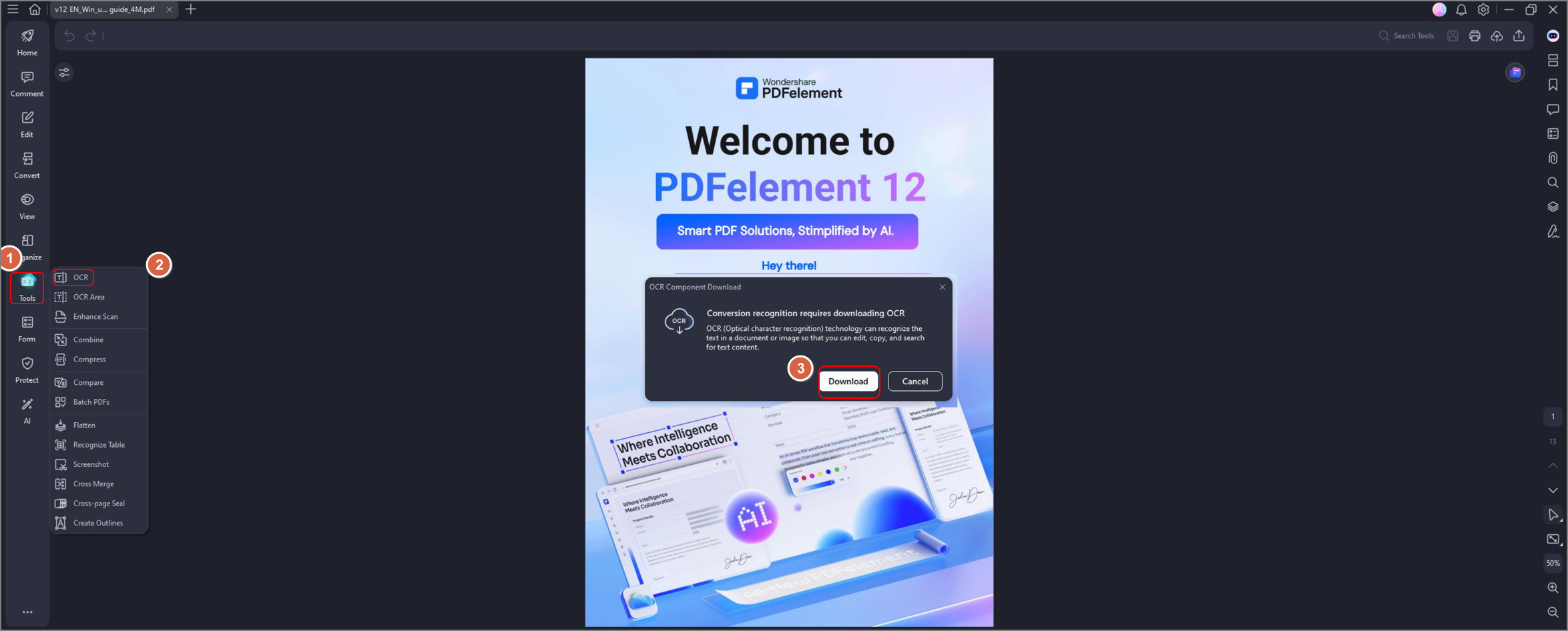
Шаг 3 После завершения установки вы можете преобразовать документ в текстовый файл. Нажмите на кнопку OCR, которая приведет вас к этому выбору:
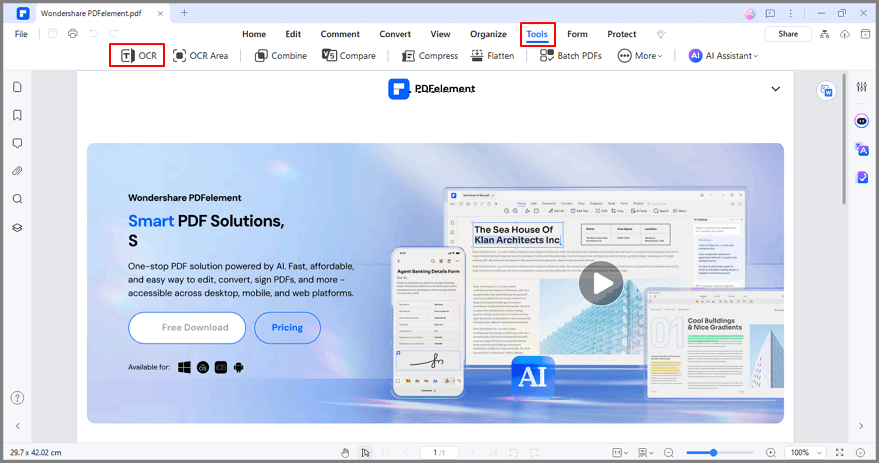
Шаг 4 После завершения извлечения PDF-документа выберите формат, в который вы хотите преобразовать документ.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Если вы используете бесплатную пробную версию, вы можете использовать функцию OCR для ограниченного количества преобразований и функций. Возможно, вы захотите заплатить за его Pro-версию, чтобы получить максимальную отдачу от этого приложения.
Помимо настольных компьютеров, мобильные пользователи также могут установить это программное обеспечение на свои устройства. Пользователи также могут использовать это приложение в облаке.
Заключение
Для людей и компаний, которые часто работают с документами любой формы, OCR для файлов PDF и изображений необходимы для повышения производительности. Эти приложения позволяют извлекать символы из файлов и превращать их в машиночитаемый текст. Если вам нужно качественное программное обеспечение OCR, которое будет удобным в использовании и достаточно надежным для ваших высоких требований, PDFelement - ваш разумный выбор.

Wondershare PDFelement - Интеллектуальные PDF-решения, упрощенные с помощью ИИ
Преобразование стопок бумажных документов в цифровой формат с помощью функции распознавания текста для лучшего архивирования.
Различные бесплатные PDF-шаблоны, включая открытки с пожеланиями на день рождения, поздравительные открытки, PDF-планировщики, резюме и т.д.
Редактируйте PDF-файлы, как в Word, и легко делитесь ими по электронной почте, с помощью ссылок или QR-кодов.
ИИ-Ассистент (на базе ChatGPT) напишет, отредактирует и переведет ваш контент, чтобы сделать его прекрасным и особенным.
