
PDFelement - мощный и простой PDF-редактор
Начните работу с самым простым способом управления PDF-файлами с помощью PDFelement!
Оптическое распознавание символов (OCR) - это технология, которая позволяет вамизвлечение текста из изображений. OCR может распознавать печатные или рукописные символы на изображениях и извлекать их. Затем извлеченный текст можно отредактировать и поделиться им с помощью других приложений, например, текстового редактора.
Многие инструменты поддерживают OCR. Однако большинство коммерческих OCR-движков не являются бесплатными или имеют ограничения на свободное использование. К счастью, благодаря усилиям многих исследователей и сообщества с открытым исходным кодом, вы можете бесплатно протестировать или использовать несколько отличных OCR-движков с открытым исходным кодом.
Python - это простой в использовании и эффективный язык программирования, который особенно популярен в обработке текстов и изображений. Благодаря огромному количеству доступных библиотек, Python может автоматически выполнять за вас различные типы задач, включая преобразование изображения в текст. В этой статье описывается, как использовать Python с двумя популярными OCR-движками для извлечения текста из изображений.
В этой статье
Как извлечь текст из изображений с помощью Python
Используйте Тессеракт
Тессерактэто популярный OCR-движок с открытым исходным кодом, который был предварительно обучен для поддержки более 100 языков. В этой статье мы используем Python-tesseract (pytesseract), обертку Python для Tesseract, которая позволяет использовать Tesseract с Python. Все действия, описанные в этой статье, выполняются на ПК с ОС Windows.
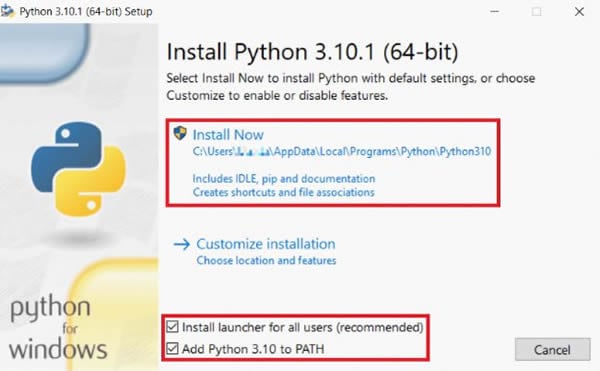
Шаг 1Загрузите и установитеPython.
Для использования pytesseract требуется Python 3.6+. Поэтому убедитесь, что вы установили версию позже, чем 3.6. Затем в окне установки выберитеДобавьте Python X.XX в PATHчтобы автоматически добавить Python в системный путь. В противном случае вы должны вручную настроить системный путь после установки Python.
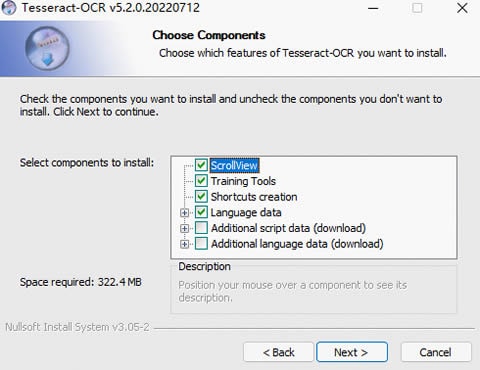
Шаг 2Загрузите и установите Tesseract.
Вы можете загрузить последнюю версию установочного пакета Tesseract для Windowsздесь. Далее в окне установки выберите дополнительные языки и скрипты, которые вы хотите установить. По умолчанию можно установить только английский язык.
Tesseract предоставляет удобный инструмент командной строки, который можно использовать для выполнения OCR на изображениях. После установки Tesseract откройте окно CLI, перейдите в папку, где находится файл изображения, текст которого вы хотите извлечь, и выполните следующую команду:
tesseract <имя файла изображения> out
Эта команда извлекает текст из указанного изображения и сохраняет его в файлеout.txtфайл. Чтобы использовать Tesseract с Python, перейдите к следующему шагу для установки необходимых пакетов Python.
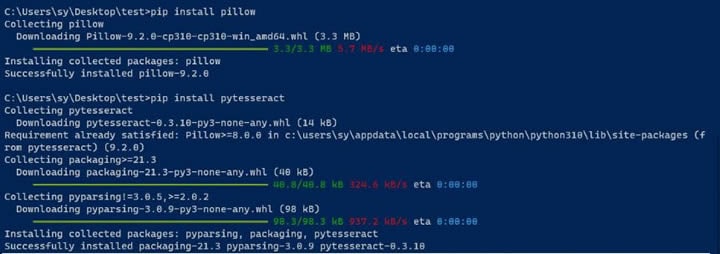
Шаг 3Установите пакеты Pillow и pytesseract.
Pillow используется для обработки изображений, а pytesseract необходим для использования Tesseract с Python. Вы можете установить пакеты, выполнив следующие команды в окне CLI:
pip install pillow
pip install pytesseract
Шаг 4Напишите код Python для извлечения текста из изображений.
После установки пакетов вы готовы к написанию кода на Python для извлечения текста из изображений. Перейдите в папку, где хранятся файлы изображений, из которых вы хотите извлечь текст. Создайте текстовый файл и измените его имя наextract.py. Вы можете изменить текстовый файл на любое имя, но убедитесь, что расширение имени файла являетсяpy.
С помощью текстового редактора, например, Блокнота, откройте файлextract.pyфайл. Скопируйте в файл следующий пример кода и сохраните файл:
из PIL import Image
импортировать pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
Для успешного выполнения предыдущего сценария у вас должен быть файл изображения с именемtest.jpgв той же папке, что иextract.pyфайл. В данной статье в качестве примера используется следующее изображение.

Откройте окно CLI, перейдите в папку, где находится файл изображения, а затем выполните следующую команду:
python extract.py
Вы должны получить следующий вывод команды.
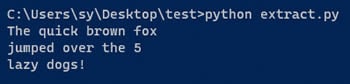
Результат показывает, что текст успешно извлечен из изображения. На этом базовый процесс использования Tesseract с Python завершен. Для получения дополнительной информации о том, как использовать pytesseract, смотрите его документацию.
Если вы хотите извлечь текст из нескольких изображений в пакетном режиме, простой способ - добавить имена файлов в TXT-файл, например, такimages.txt. Например:
test.jpg
test1.jpg
Затем изменитеextract.pyфайл следующим образом:
из PIL import Image
импортировать pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Когда вы запускаете предыдущий сценарий, текст извлекается из всех изображений, которые указаны в параметреimages.txtфайл.
Используйте EasyOCR
EasyOCRэто пакет для Python, который предоставляет готовый к использованию механизм OCR и поддерживает 80+ языков. EasyOCR легко устанавливается и очень прост в использовании. Это делает его отличным решением для выполнения OCR с помощью Python. Вам нужно только установить пакеты PyTorch (требуется только для Windows) и EasyOCR, а затем вы можете начать извлекать текст из изображений с помощью Python.
Шаг 1Установите необходимые пакеты Python.
Чтобы использовать EasyOCR в Windows, необходимо установить пакеты PyTorch и EasyOCR. Последовательно выполните следующие команды для установки пакетов:
pip install torch torchvision torchaudio
pip install easyocr
pip install torch torchvision torchaudio
pip install easyocr
Шаг 2Напишите код на языке Python для использования EasyOCR.
Перейдите в папку, в которой находится ваше изображение,создайте файл .py, напримерextract.py, а затем скопируйте в файл следующий пример кода:
импортировать easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
На следующем рисунке показан вывод команды при выполнении командыextract.pyfile.

Как показано в выводе команды, текст извлечен из тестового изображения.
Преимущества и недостатки использования Python
Python - это язык программирования, который легко изучить и использовать. Он широко используется в глубоком обучении и обработке естественного языка. По сравнению с другими языками, код Python зачастую проще и короче. Однако изучение Python требует времени, и вам необходимо изучить OCR-движки, которые вы хотите использовать с Python.
Преимущества использования Python для извлечения текста из изображений:
- Такие механизмы OCR, как Tesseract и EasyOCR, можно использовать бесплатно.
- Python подходит для пакетных и повторяющихся задач OCR.
- С помощью Python можно эффективно и быстро обрабатывать большое количество изображений.
- Вы можете получить результаты преобразования звука, настроив параметры механизма OCR ts.
- Вы можете сохранить хорошо разработанный сценарий Python и использовать его всякий раз, когда вам понадобится извлечь текст из изображений. Вы также можете поделиться сценарием с другими людьми, у которых такие же требования к конвертации.
Недостатки использования Python для извлечения текста из изображений:
- Требуется знание языка Python.
- Необходимо провести исследование движков OCR, которые вы хотите использовать.
- OCR-движки с открытым исходным кодом могут быть не такими точными, как коммерческие. Кроме того, некоторые не могут распознать почерк.
Тем не менее, всегда полезно узнать что-то новое. Кроме того, при необходимости вы всегда можете переключиться на другие инструменты. Существует множество существующих инструментов, которые помогут вам быстро извлечь текст из изображений. Вы можете выбрать один из них в зависимости от ваших требований.
Как извлечь текст из изображений без Python
Если вы не любитель программирования и ищете готовый инструмент,Wondershare PDFelement - Редактор PDF-файловis a quick and easy app that you should check out.
PDFelement - это быстрый и универсальный редактор PDF, который позволяет просматривать, редактировать и конвертировать PDF-файлы. PDFelement также оснащен усовершенствованным механизмом OCR, который можно использовать для точного и эффективного извлечения текста из изображений.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
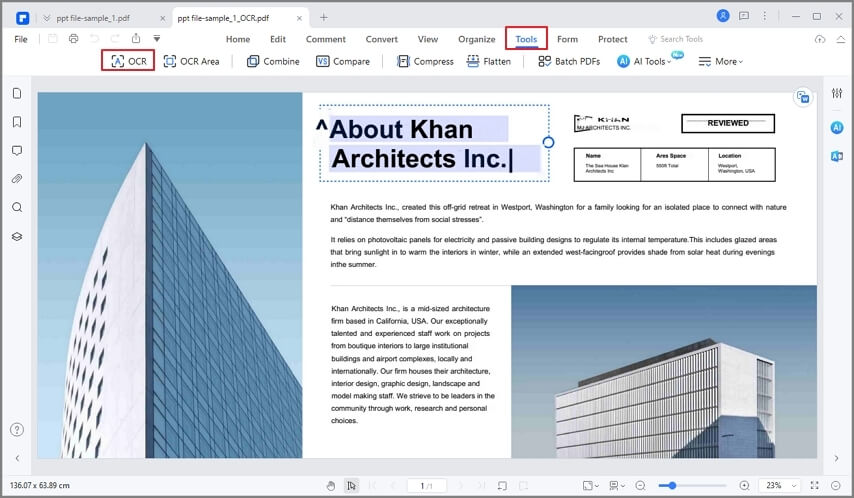
Для извлечения текста из изображений в PDFelement можно выполнить следующие действия:
Шаг 1ОткрытьPDF-элемент. Перетащите файл изображения, из которого нужно извлечь текст, в окно PDFelement. Вы также можете выбратьСоздать PDF> Из файла и выберите файл изображения. Затем PDFelement преобразует изображение в PDF и открывает его в новой вкладке.
Шаг 2В меню Инструменты нажмите OC, чтобы выполнить OCR на изображении. Это позволяет PDFelement распознавать все символы на изображении и превращать их в редактируемый и доступный для поиска текст.
Шаг 3Скопируйте текст в нужное место и отредактируйте его. Вы также можете конвертировать PDF с редактируемым текстом в другие форматы, такие как Word или Excel.
В дополнение к механизму OCR, PDFelement также предоставляет другие функции, которые помогут повысить вашу производительность:
- Открывайте и просматривайте файлы PDF на высокой скорости
- Редактирование содержимого PDF-файлов, например, текста и изображений
- Преобразование PDF в различные форматы, такие как EPUB и Word
Заключение
Python - отличный язык программирования, который подходит для автоматизации повторяющихся задач. Используя Python, вы можете легко и быстро извлекать текст из изображений с помощью OCR-движков с открытым исходным кодом. В этой статье рассказывалось о том, как вызвать возможности OCR в Tesseract и EasyOCR с помощью Python.
Однако извлечение текста из изображений с помощью Python предполагает программирование, что требует базовых знаний программирования и языка Python. Если у вас нет знаний в области программирования, существует множество других вариантов для полного извлечения текста из изображений. Отличным вариантом для рассмотрения является PDFelement - продвинутое и сложное приложение, которое поможет вам легко и эффективно извлечь текст из изображений.
