
В современном мире, ориентированном на работу с данными, извлечение информации из PDF-документов может отнимать много времени и приводить к ошибкам. Вручную копировать и вставлять данные из сотен или тысяч PDF-файлов утомительно и может привести к неточностям и несоответствиям в ваших данных. Однако с помощью автоматизации вы можете оптимизировать процесс извлечения данных из PDF и сэкономить свое драгоценное время и силы.
Автоматизация извлечения данных из PDF может дать множество преимуществ, от повышения точности и эффективности до увеличения производительности и масштабируемости. Устранив необходимость ручного ввода данных, вы снизите риск ошибок и освободите свое время, чтобы сосредоточиться на более важных задачах. В этой статье мы шаг за шагом рассмотрим процесс автоматизации извлечения данных из PDF.

Преимущества автоматического извлечения данных из PDF-файла
Автоматизация извлечения PDF-данных может обеспечить различные преимущества, что делает ее ценным инструментом для предприятий и частных лиц. Automation of PDF data extraction can provide various benefits, making it a valuable tool for businesses and individuals. Вот некоторые из ключевых преимуществ автоматизации извлечения данных в формате PDF:
Экономия времени: извлечение данных из PDF-файлов вручную может занять много времени, особенно если вам приходится обрабатывать большие документы. Автоматизировав этот процесс, вы сможете значительно сократить время и усилия, необходимые для извлечения данных из PDF-файлов, высвободив свое время для решения более важных задач.
Повышенная точность: Ручное копирование и вставка PDF-данных могут привести к ошибкам, особенно если вам необходимо обработать большие объемы документов. Автоматизировав этот процесс, вы сможете исключить риск ошибок и обеспечить точность и последовательность данных.
Повышение производительности: Автоматизация извлечения данных из PDF может помочь вам повысить производительность труда за счет оптимизации рабочего процесса и сокращения времени и усилий, необходимых для выполнения рутинных задач. Это поможет вам добиться большего за меньшее время, позволяя сосредоточиться на более важных проектах и целях.
Автоматизированное извлечение данных из PDF может быть особенно полезным в различных ситуациях. Например, если вы работаете в сфере финансов или бухгалтерии, вам может потребоваться регулярно извлекать данные из сотен или тысяч счетов или квитанций. Автоматизация этого процесса поможет вам сэкономить время и сократить количество ошибок, повысив эффективность ваших операций.
Аналогично, если вы работаете в сфере маркетинга или продаж, вам может понадобиться извлечь данные из форм обратной связи с клиентами, опросов или других документов. Автоматизация этого процесса поможет вам быстрее и эффективнее анализировать данные, что позволит выявить тенденции, понять суть и возможности для улучшения.
Автоматизация извлечения данных из PDF может стать ценным инструментом для тех, кому необходимо регулярно извлекать данные из PDF-файлов. Независимо от того, являетесь ли вы владельцем малого бизнеса, фрилансером или крупной корпорацией, автоматизация поможет вам улучшить рабочий процесс, сэкономить время и добиться лучших результатов.
Как получить автоматическое извлечение данных из PDF
Теперь, когда мы рассмотрели преимущества автоматизации извлечения данных из PDF, давайте посмотрим, как можно начать этот процесс. В этом разделе мы рассмотрим пошаговый процесс использования автоматического извлечения данных из PDF-инструмента.
Метод 1: Используйте инструмент автоматического извлечения данных PDFelement
Wondershare PDFelement - Редактор PDF-файлов — это популярный PDF-редактор с расширенными возможностями, включая инструмент автоматического извлечения данных. Этот инструмент позволяет автоматически извлекать данные из PDF-файлов, используя настраиваемые шаблоны, которые могут распознавать и извлекать определенные типы данных, такие как имена, адреса и номера телефонов.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Чтобы воспользоваться инструментом автоматического извлечения данных в PDFelement, выполните следующие действия:
Извлечение данных из полей PDF-формы
Этот процесс подходит, если PDF-файл представляет собой заполняемую форму.
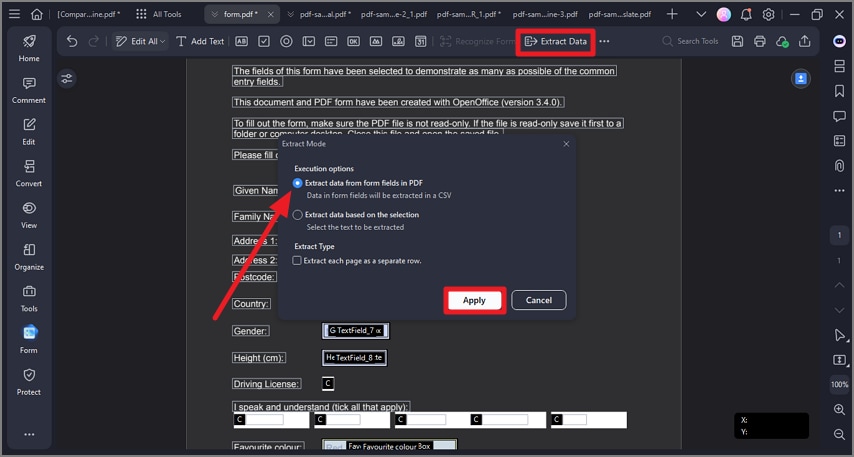
Шаг 1 Запустите PDFelement и нажмите "Форма".
Шаг 2 Выберите опцию "Извлечь данные".
Шаг 3 Выберите "Извлечь данные из полей формы в PDF".
Шаг 4 Нажмите кнопку "Применить".
Извлечение данных из выбранного теста PDF
Если ваш PDF-файл не является заполняемой формой, вы можете извлечь данные из отмеченных областей PDF-файла.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
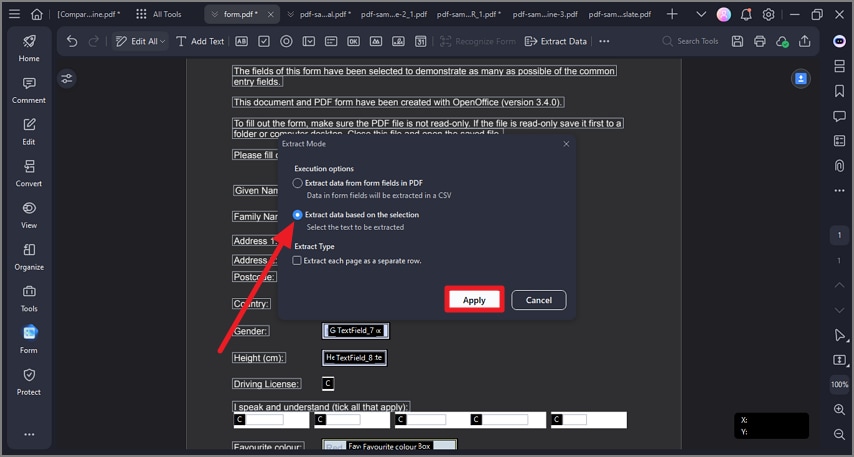
Шаг 1 Запустите PDFelement и нажмите кнопку "Форма" > "Извлечь данные" > "Извлечь данные на основе выбора" > "Применить".
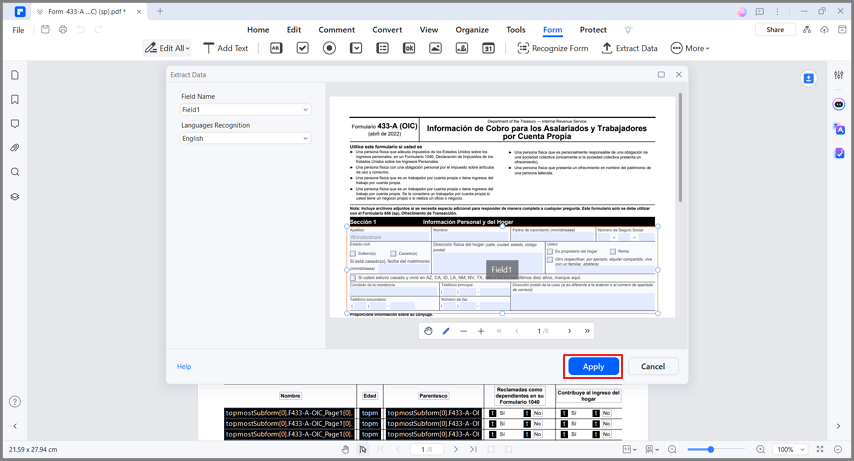
Шаг 2 Выберите область на странице, которую нужно извлечь. Установите язык на вкладке "Распознавание языка" и нажмите "Применить".
Извлечение данных для пакетной обработки
Вы можете использовать инструмент пакетной обработки, если у вас есть несколько PDF-файлов, из которых нужно извлечь данные.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Шаг 1 Запустите PDFelement и нажмите "Инструмент" > "Пакетная обработка" > кнопку "Извлечь данные".
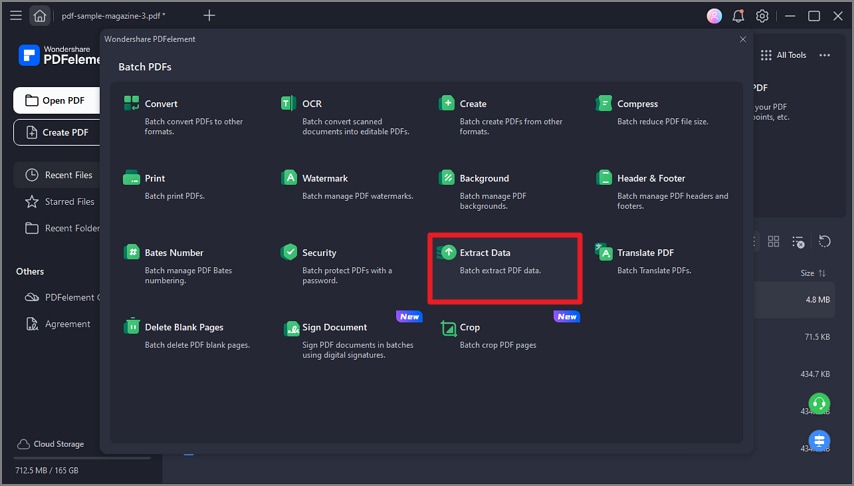
Шаг 2 Импортируйте PDF-файлы и выберите место для сохранения извлеченного файла. Нажмите кнопку "Применить", чтобы извлечь данные.
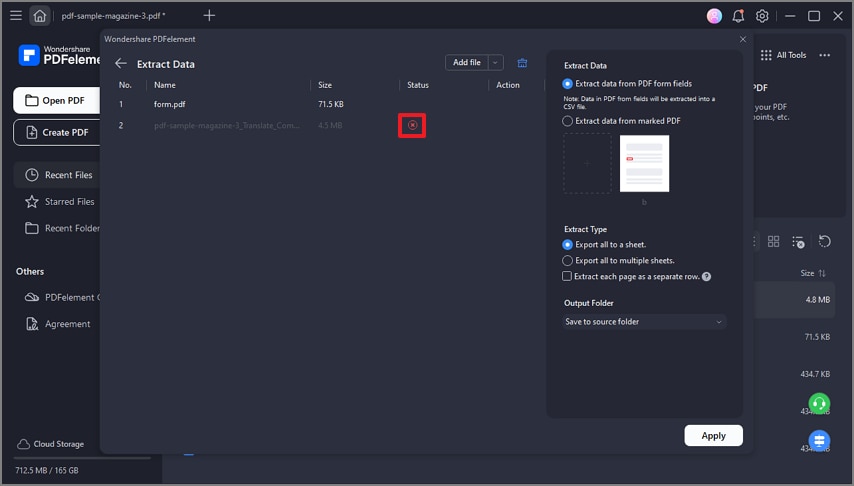
После выбора шаблона PDFelement автоматически просканирует PDF-документ на наличие соответствующих данных и извлечет их в электронную таблицу или другой формат, который вы сможете использовать для дальнейшего анализа. Вы также можете настроить свой шаблон для извлечения определенных данных или информации из PDF-документов, что делает этот метод очень гибким и настраиваемым.
Этот метод может быть особенно полезен при извлечении данных из больших объемов PDF-документов, таких как финансовые отчеты, счета-фактуры или формы обратной связи с клиентами. Автоматизация процесса извлечения данных позволяет значительно сократить время и усилия, необходимые для извлечения данных из этих документов, а также повысить точность и согласованность данных.
Метод 2: Преобразование PDF в Excel с помощью PDFelement
Преобразование PDF в Excel - еще один мощный метод извлечения данных из PDF-документов. Этот метод предполагает использование PDFelement для преобразования PDF-файла в электронную таблицу Excel, которой можно легко манипулировать и анализировать с помощью расширенных инструментов обработки данных Excel.
Вот как это сделать:
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Шаг 1 Запустите PDFelement и импортируйте PDF-файл.
Шаг 2 Нажмите "Конвертировать" > "В Excel".
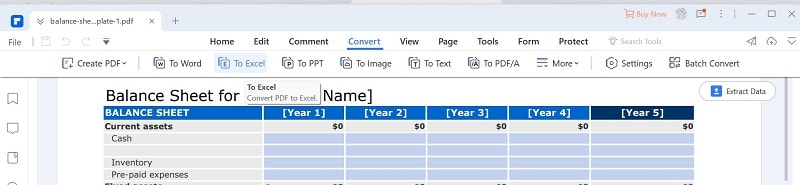
Шаг 3 Сохраните Excel. Файл PDF будет преобразован в Excel. После этого укажите целевую папку для сохранения полученного файла Excel.
Главное преимущество конвертирования PDF в Excel для извлечения данных - гибкость. С помощью Excel вы можете легко сортировать, фильтровать и анализировать данные так, как это невозможно сделать с помощью PDF-документа. Кроме того, Excel позволяет создавать графики и диаграммы для визуализации данных, что облегчает выявление тенденций и закономерностей.
Этот метод может быть особенно полезен при извлечении данных из таблиц или других структурированных данных в PDF-документе. Например, предположим, что у вас есть большой финансовый отчет, содержащий множество таблиц. Преобразование PDF в Excel позволяет легко извлекать и анализировать данные в каждой таблице отдельно.
Еще одна ситуация, в которой конвертирование PDF в Excel может оказаться полезным, - это объединение данных из нескольких PDF-документов в одну электронную таблицу. Конвертируя каждый PDF-файл в Excel и объединяя полученные электронные таблицы, вы сможете быстро и легко консолидировать данные для дальнейшего анализа.
Метод 3: Использование кодов и скриптов
Использование кодов и скриптов для автоматического извлечения данных из PDF - это очень гибкий и настраиваемый метод, который позволяет извлекать данные из PDF-документов с помощью таких языков программирования, как Python, Java или Ruby. Этот метод дает несколько преимуществ, в том числе возможность работать с большими объемами данных и настраивать процесс извлечения в соответствии с вашими конкретными потребностями.
Основные шаги по использованию кодов и скриптов для автоматического извлечения данных из PDF включают в себя использование библиотеки или модуля PDF для чтения PDF-документа и извлечения соответствующих данных. Например, вы можете использовать библиотеку PyPDF2 в Python для извлечения текста и данных из PDF-документов. Вот пример фрагмента кода, который демонстрирует, как использовать PyPDF2 для извлечения данных из PDF-документа:
import PyPDF2
pdf_file = open('example.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
страница = pdf_reader.getPage(0)
text = page.extractText()
print(text)
В этом примере мы открываем PDF-документ под названием "example.pdf" и используем PyPDF2 для извлечения текста с первой страницы документа. Затем мы можем манипулировать этим текстом, чтобы извлечь конкретные данные, которые нас интересуют.
Этот метод может быть особенно полезен, когда вам нужно извлечь данные из сложных или нестандартных PDF-документов или когда вам нужно автоматически обрабатывать большие объемы PDF-файлов. Например, предположим, что вы являетесь аналитиком данных, работающим с финансовыми отчетами или счетами-фактурами. В этом случае вы можете использовать коды и скрипты для автоматического извлечения определенных типов данных из этих документов и значительно сэкономить время и усилия.
Сравнение методов
Что касается автоматизации извлечения PDF-данных, то существует несколько методов, каждый из которых имеет свои преимущества и недостатки. Вот сравнительная таблица, в которой представлены ключевые особенности каждого метода:
Метод |
Преимущества |
Недостатки |
| Автоматическое извлечение данных из PDFelement | Простой в использовании, не требующий знаний в области программирования | Ограниченная гибкость, может работать не для всех PDF-документов. |
| Конвертируйте PDF в Excel с помощью PDFelement | Обеспечивает гибкость и передовые инструменты обработки данных | Может работать не со всеми PDF-документами, требует некоторого знания Excel |
| Используйте коды и скрипты | Легко настраиваемый, способный обрабатывать большие объемы данных | Требует знаний в области программирования, настройка может занять много времени. |
Как вы можете видеть, у каждого метода есть свои сильные и слабые стороны, и выбор наилучшего метода для вас будет зависеть от ваших конкретных потребностей и опыта. Если вы ищете простое и понятное в использовании решение, автоматическое извлечение данных из PDFelement может стать вашим лучшим выбором. Однако преобразование PDF в Excel с помощью PDFelement может оказаться более эффективным, если вам нужны более гибкие и продвинутые инструменты обработки данных.
Если вы обладаете знаниями в области программирования и вам необходимо обрабатывать большие объемы данных, использование кодов и скриптов может быть вашим наиболее эффективным методом. Однако этот метод требует больше времени на настройку и специальных знаний, чем другие методы, поэтому для некоторых из них может быть лучше выбрать другой.
Заключение
Автоматизация извлечения данных в формате PDF может сэкономить ваше время и повысить точность анализа данных. Среди представленных методов PDFelement является мощным инструментом автоматического извлечения и преобразования данных. Благодаря удобному интерфейсу и передовым инструментам обработки данных PDFelement поможет вам оптимизировать рабочий процесс и повысить производительность.
