Я много работаю с патентным ведомством США, которое включает в себя множество файлов, не относящихся к OCR. Может ли кто-нибудь предложить хорошую программу пакетное распознавание текста PDF файлы? Точность важна. Что вы мне можете посоветовать?
Применение OCR позволяет сделать отсканированные файлы PDF доступными для поиска и редактирования с использованием технологии оптического распознавания символов (OCR). У вас может быть несколько файлов в офисе, которые вы назначили для OCR в течение нескольких часов, и вам нужен более быстрый способ сделать это. Что ж, решение заключается в пакетном распознавании с использованием программного обеспечения. В этом руководстве мы расскажем вам о двух способах пакетного преобразования PDF в PDF с возможностью поиска с использованием PDFelement и Adobe Acrobat.


Как осуществить пакетную обработку OCR PDF-файлов
Первый способ, которым мы собираемся рассмотреть, чтобы пакетно преобразовать OCR из PDF, - это использование PDFelement. Загрузите версию, совместимую с вашей операционной системой, и установите ее. После того, как вы установили программу, вы можете следовать этому руководству и изучить быстрый способ пакетной обработки OCR.
Шаг 1. Нажмите «Пакетная обработка»
Сначала откройте приложение на вашем компьютере. Вы окажетесь на главном экране приложения. Нажмите на кнопку «Пакетная обработка» и перейдите к следующему шагу.
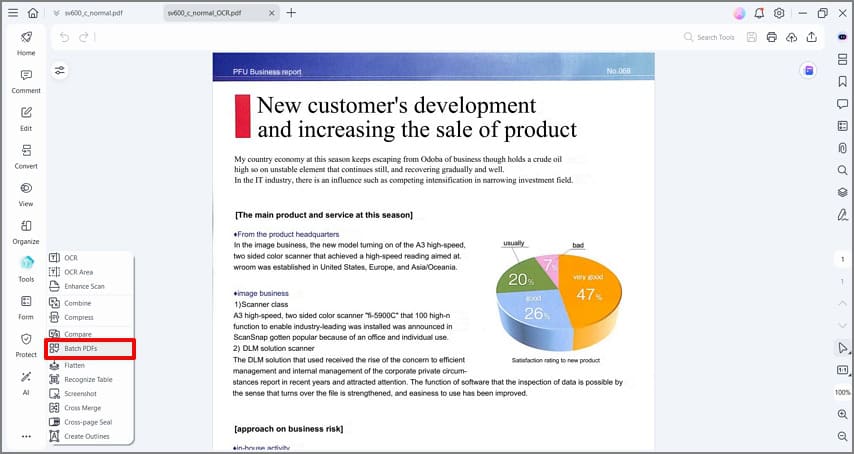
Шаг 2. Добавьте несколько отсканированных файлов
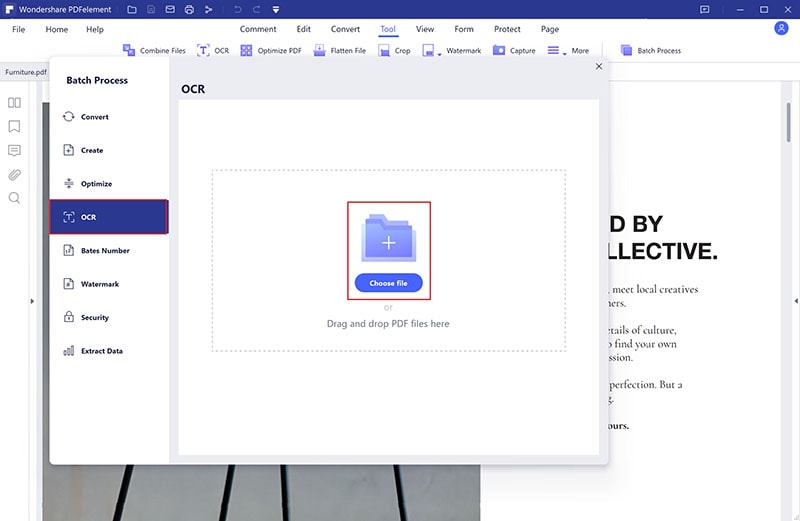
На появившемся экране пакетного процесса нажмите «OCR», а затем нажмите «Добавить PDF-файлы здесь». Теперь выберите как можно больше файлов PDF и добавьте их в программу. Проще упорядочить файлы PDF в папке, так что вы можете загрузить их сразу.
Шаг 3. Выберите Язык пакетной обработки OCR
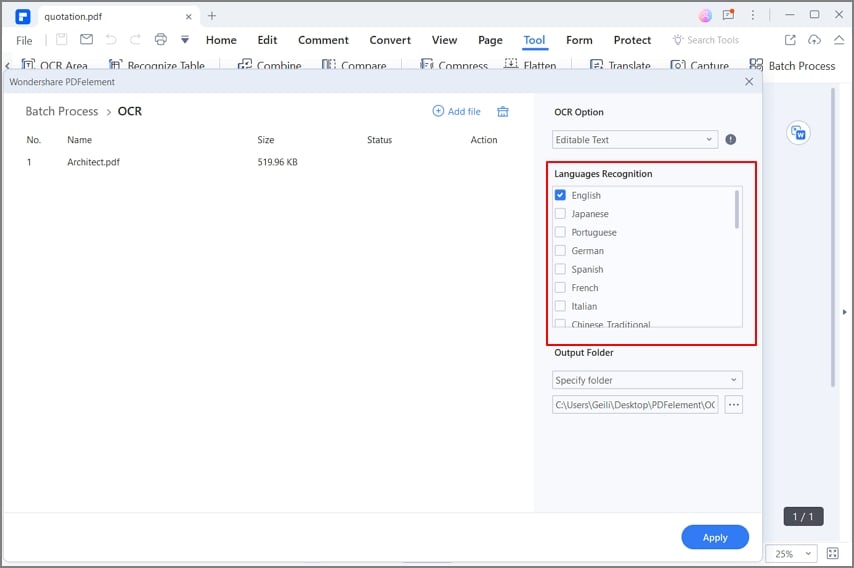
После загрузки файлов PDF в программу, вам нужно выбрать язык, который вы должны использовать для выполнения языка OCR. Обычно это зависит от языка документов. Перейдите вправо и под опцией OCR и отметьте на текущем языке, например, «Английский».
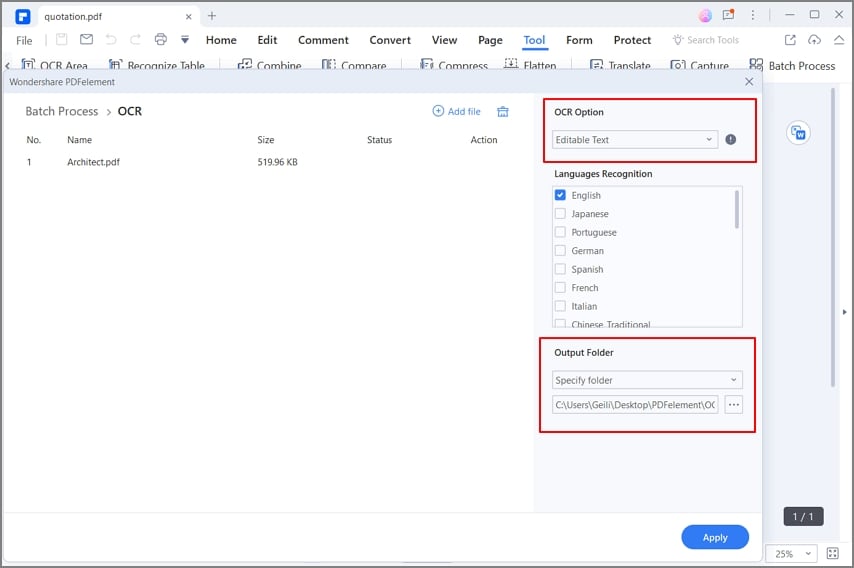
Шаг 4. Установите конечную папку для пакетного распознавания текста
Далее вам нужно установить конечную папку для пакетных файлов OCR. Чуть ниже опция языка OCR - опция вывода. Отметьте «Папка на моем компьютере», если вы хотите изменить место назначения папки. В противном случае, чтобы сохранить папку, установите флажок «Та же папка, которая выбрана в качестве начальной».
После этого нажмите «Пуск», чтобы выполнить массовую распечатку PDF-файлов.
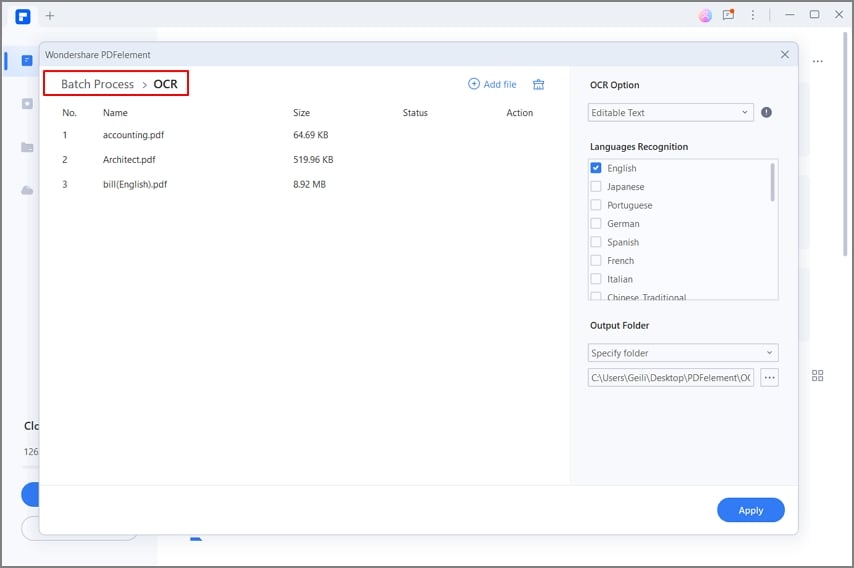
Шаг 5. Завершите процесс пакетного распознавания текста
Это пакетное программное обеспечение OCR немедленно запустит процесс, и процесс будет отображаться на экране. Как только все загруженные вами PDF-файлы будут успешно обработаны, нажмите кнопку «Готово». Это откроет папку назначения для вас.
Шаг 6. Отредактируйте файл PDF после выполнения OCR
Прекрасно! На данный момент ваши PDF-файлы теперь доступны для редактирования и поиска. Перейдите в папку, которую вы определили ранее при сохранении файлов OCR, и откройте файлы с помощью PDFelement.
Затем нажмите кнопку «Редактировать» в главном меню, чтобы выбрать режим редактирования в режиме строки или в режиме абзаца. Оттуда перейдите к абзацу, который вы хотите изменить, и щелкните по нему. Вы можете вернуться назад, чтобы удалить тексты, добавлять новые тексты, ссылки и изображения легко.
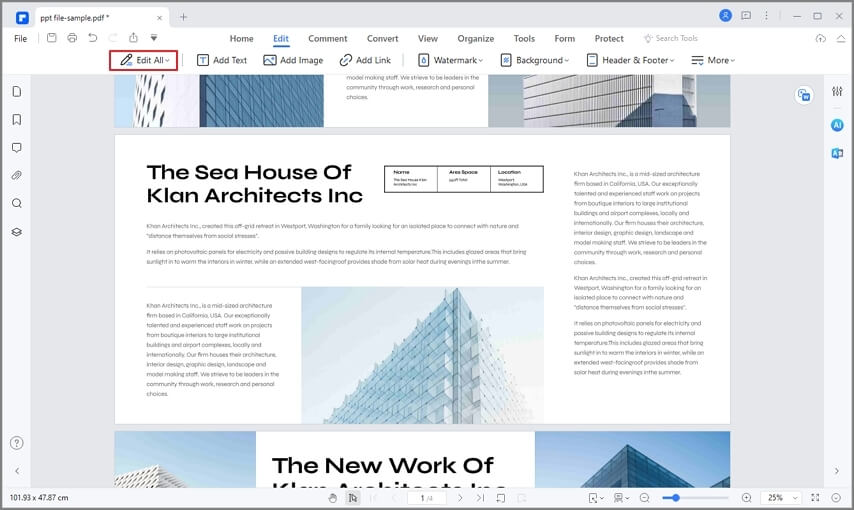
Как только вы закончите редактирование, не забудьте сохранить файл PDF!
Изучая мощную функцию пакетного распознавания текста PDFelement, вам, возможно, нужно больше узнать о PDFelement. Это утилита PDF, созданная с несколькими возможностями PDF, начиная от создания файлов PDF, редактирования файлов PDF и заканчивая совместным использованием файлов. С помощью функции OCR вы можете сканировать тексты на разных языках в пакете и сохранять их в нужной папке. Другие особенности этого программного обеспечения:
- Конвертирует PDF-файлы в редактируемые выходные форматы, такие как Excel, Word, PPT, HTML, изображения, обычные тексты и EPUB.
- Создает файлы PDF из шаблонов PDF, сканеров, принтеров и файлов любого формата.
- Редактирует содержимое PDF, такие, как тексты, изображения, объекты, ссылки и страницы.
- Заполняет форму, извлекает данные из форм и создает формы.
- Объединяет файлы в файлы PDF.
- Шифрует PDF-файлы цифровыми подписями, водяными знаками и редактирует их.
- Позволяет делиться файлами PDF через электронную почту и облачное хранилище.
Как пакетно распознать файлы PDF с помощью Adobe Acrobat
Adobe Acrobat также имеет пакетную функцию распознавания текста, которая упрощает вашу работу. Процесс также прост и понятен, если у вас есть это программное обеспечение. Вот руководство к процессу распознавания Adobe Acrobat.
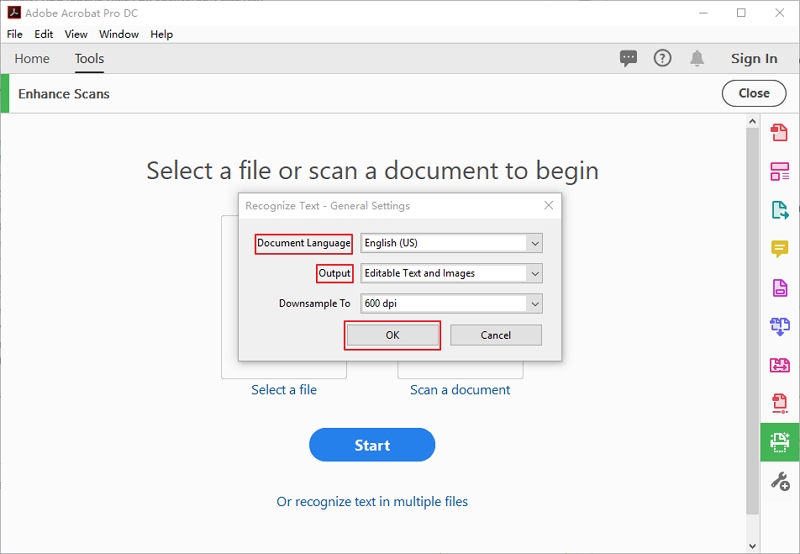
Шаг 1. Загрузите и установите Adobe Acrobat на свой компьютер. Далее откройте его и нажмите «Улучшить сканирование».
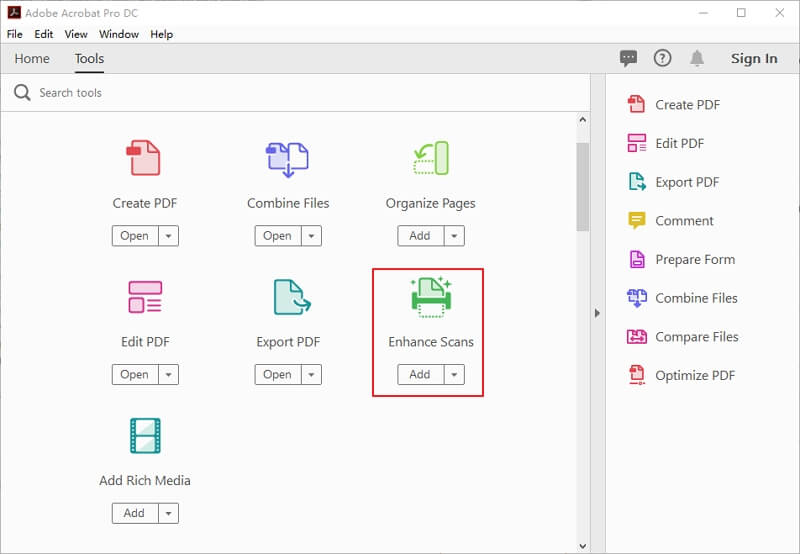
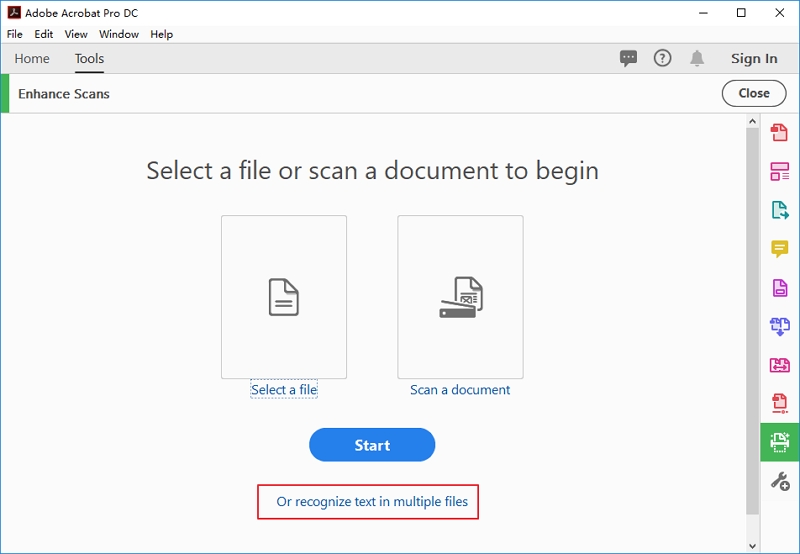
Шаг 2. Затем нажмите «Распознать текст в нескольких файлах», чтобы иметь возможность добавлять файлы в Adobe Acrobat.
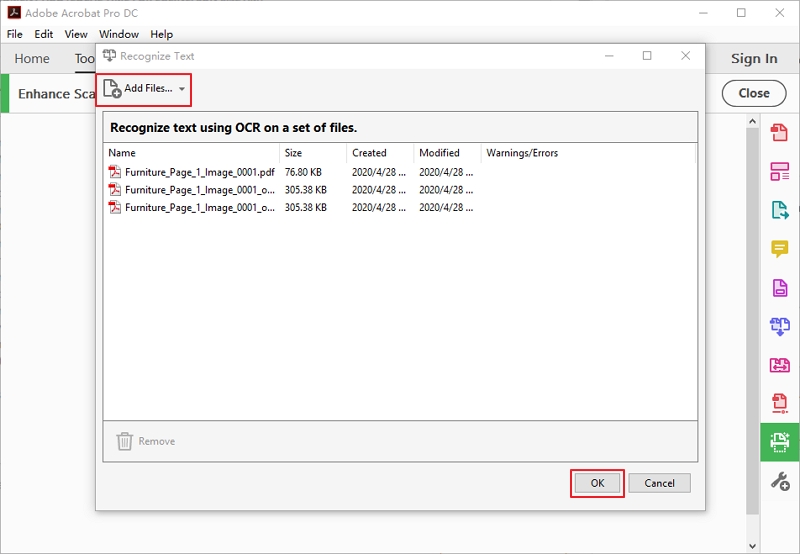
Шаг 3. Появится всплывающее окно, позволяющее добавить несколько файлов. Нажмите «Добавить файлы» и выберите столько файлов PDF, сколько хотите, а затем нажмите кнопку «ОК» после загрузки.
Шаг 4. После этого вам нужно указать свои настройки вывода. Выберите «Целевую папку» и укажите «Имена файлов». Также решите, хотите ли вы «Перезаписать существующие файлы».
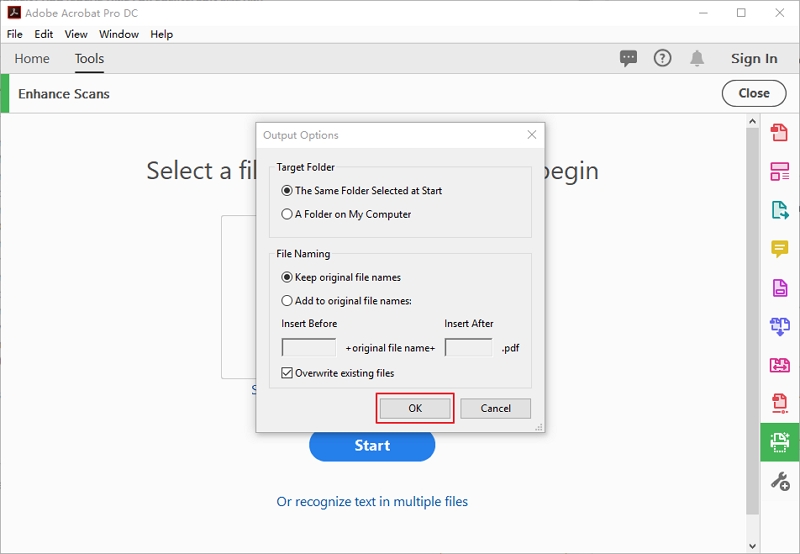
Шаг 5. Наконец, выберите язык OCR в зависимости от языка текста ваших файлов OCR. Затем выберите параметры вывода и нажмите «ОК» для завершения процесса пакетного распознавания Adobe. Затем нажмите «Пуск» для пакетного распознавания файлов в Adobe Acrobat.