Испытываете сложности при работе с отсканированными PDF-файлами? Ищете способ быстро преобразовывать отсканированные PDF в текст? Мы предлагаем два эффективных решения данной проблемы. Сначала мы поговорим о том, как распознавать текст в Google Drive, а затем я представлю вам лучшее решение этой задачи - PDFelement.


Как использовать альтернативы Google Диска для распознавания текста
PDFelement сочетает функции создания, редактирования, аннотирования и преобразования файлов в одной программе. Функция OCR в данной программе позволяет с легкостью распознавать ваши отсканированные или основанные на изображениях PDF-документы и превращать их в редактируемый текст. Функция распознавания текста поддерживает широкий спектр языков, таких как английский, корейский, немецкий, румынский, итальянский, португальский, испанский и другие.
Шаг 1. Открытие отсканированного PDF-файла
После установки PDFelement откройте отсканированный PDF-документ с помощью этой программы. Для этого вы можете нажать кнопку «Открыть файл...» и ваш файл будет открыт прямо в PDFelement.
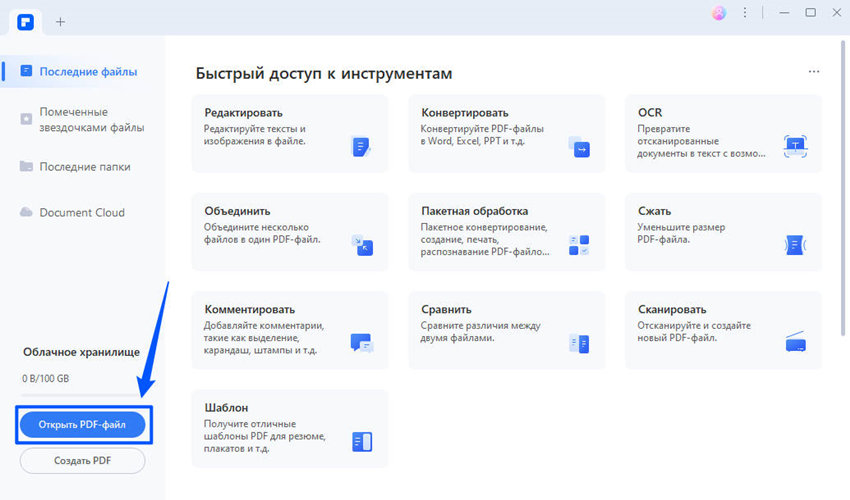
Шаг 2. Распознавание текста PDF без конвертирования
Программа напомнит вам выполнить распознавание текста после загрузки отсканированного PDF. Нажмите кнопку «Распознать текст» в верхней информационной панели и выберите нужный язык. Через некоторое время отсканированный PDF будет преобразован в редактируемый формат. Если вам нужно внести изменения в получившийся документ, нажмите «Редактировать» в левом верхнем углу экрана.
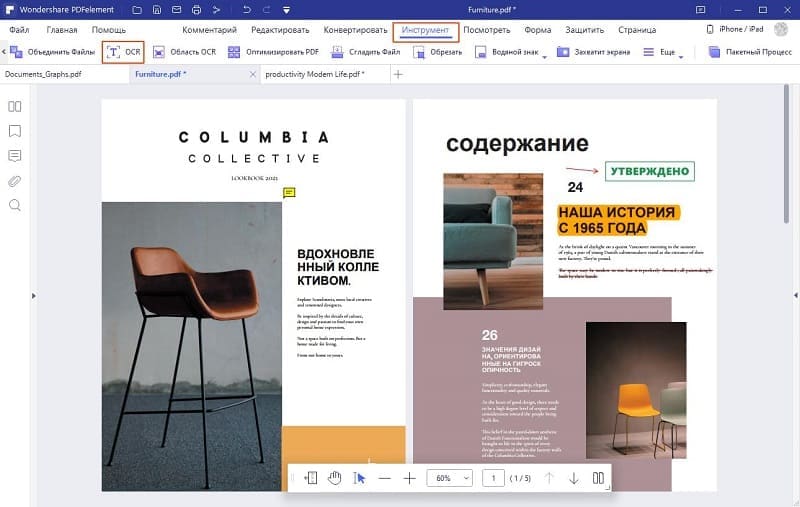
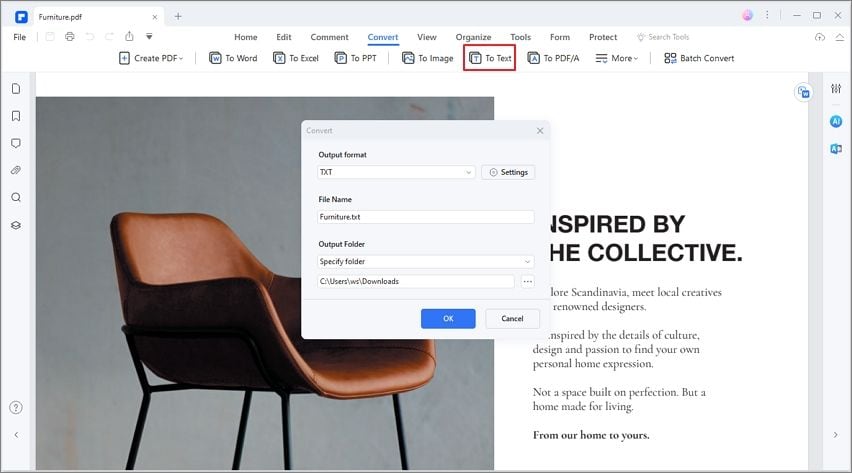
Шаг 3. Конвертирование PDF в текст с помощью функции распознавания текста
Если вам нужно экспортировать отсканированный PDF в текстовый формат, перейдите во вкладку «Главная», нажмите кнопку «В другие формату» и выберите опцию «Преобразовать в текст». Затем установите флажок «Настройки» > «Включить распознавание» во всплывающем окне. Нажмите «Сохранить», чтобы запустить процесс распознавания.
Чтобы установить язык распознавания, перейдите в меню «Файл > Настройки» и выберите нужный язык во вкладке «Распознавание (OCR)».
Благодаря мощному функционалу вы можете редактировать текст PDF, менять изображения и размечать контент с легкостью. Помимо редактирования вы можете аннотировать, шифровать PDF, конвертировать в другие форматы, создавать заполняемые формы и т.д.

Как использовать Google Диск для распознавания текста
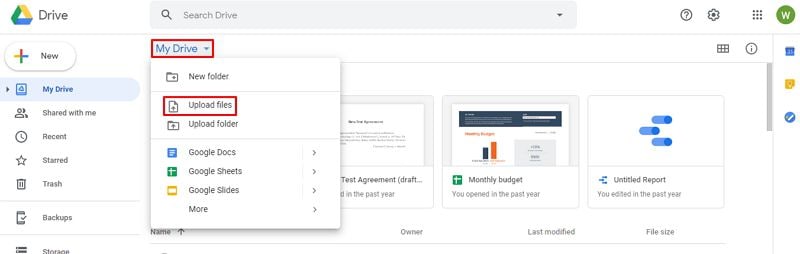
Шаг 1. Импортирование PDF-файла, созданного на основе изображений
После входа в учетную запись Google Диск вы можете загрузить в нее свое изображение или отсканированный файл.
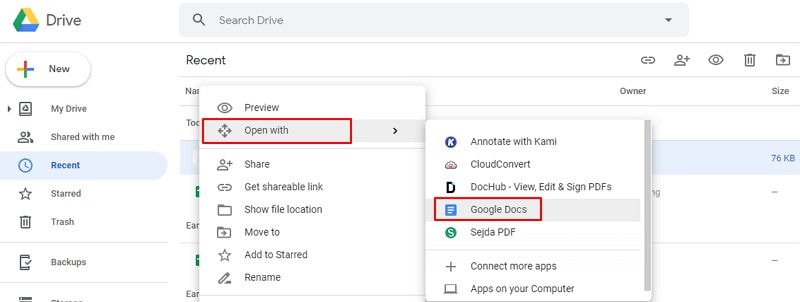
Шаг 2. Распознавание текста в Google Документах
Выберите загруженный файл и откройте его с помощью Google Документы. При открытии файла в Google Документах подключается опция распознавания символов Google Drive OCR. Текст в файле с изображениями теперь можно редактировать.
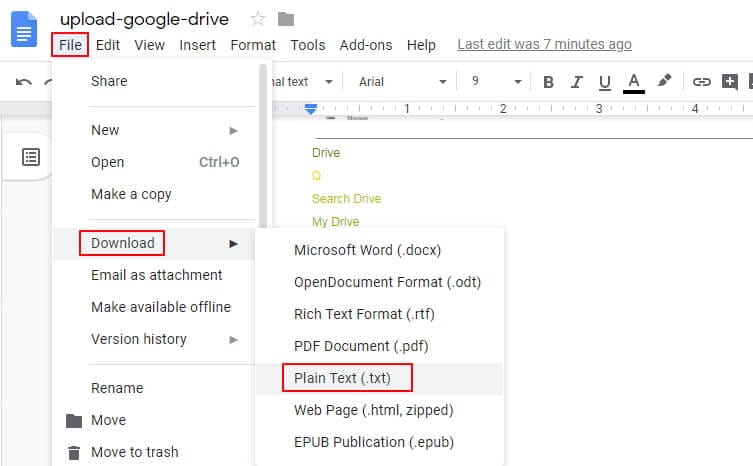
Шаг 3. Сохранение файла
Нажмите кнопку «Файл» > «Скачать», чтобы выбрать формат его сохранения на своем компьютере.
Вот как можно использовать функцию распознавания символов Google Docs для преобразования отсканированного PDF в текст. Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.