
OCR или оптическое распознавание символов - это вычислительный процесс, который преобразует символы на основе изображений в редактируемый или доступный для поиска текст. Обычно он используется для отсканированных файлов PDF, или даже для файлов изображений, содержащих текст. OCR очень полезно при преобразовании физических документов или нередактируемых цифровых файлов в PDF файлы, с которыми Вы действительно можете работать, используя редактор PDF или программу для чтения PDF. Некоторые варианты использования OCR:
- Преобразование бумажных счетов фактур в цифровой формат
- Сканирование и преобразование заполненных вручную форм
- Преобразование содержимого из неинтерактивного состояния в интерактивное, например преобразование книги в электронную книгу.
Каким бы ни был сценарий, давайте не будем забывать, что наиболее важным аспектом выбора инструмента для распознавания текста является уровень точности. Для этого мы рекомендуемWondershare PDFelement - Редактор PDF-файлов, который доступен как для систем Windows, так и для Mac и может похвастаться одним из самых высоких показателей точности распознавания текста в отрасли. Кроме того, он позволяет преобразовывать текст на основе изображений в формат с возможностью поиска или редактирования в зависимости от цели преобразования.
Часть 1. Как Оптически Распознать Документ или Изображение в PDFelement
Выполнить распознавание текста в документе несложно, потому что PDFelement точно сообщает Вам, что делать. В тот момент, когда Вы открываете нередактируемый PDF файл или используете Создать PDF для преобразования изображения в PDF, он распознает это и предлагает Вам установить плагин OCR и выполнить OCR. Вот что Вы увидите на своем экране:
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
1. Для файлов изображений используйте кнопку «Создать PDF» на странице приветствия, чтобы добавить свои JPG, PNG и т.д., нажмите «Создать», чтобы преобразовать их в PDF и открыть в PDFelement. Для нередактируемых PDF файлов просто используйте опцию «Открыть файлы», чтобы извлечь файл из папки.
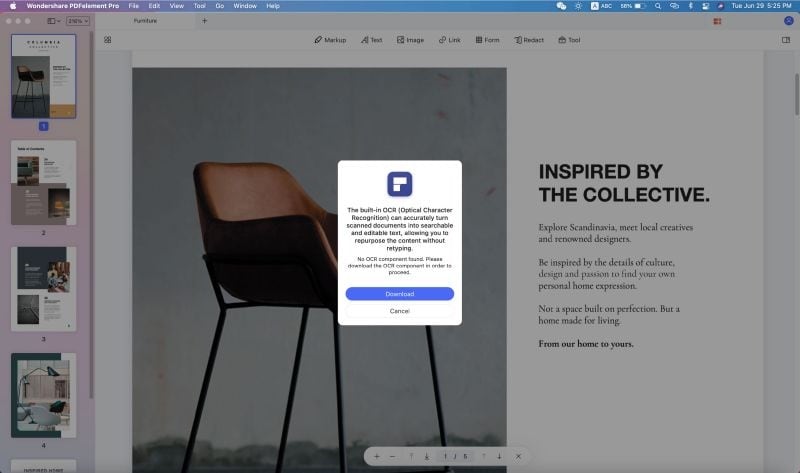
2. Как только файл откроется, Вы увидите сообщение «Выполнить распознавание текста» на панели уведомлений над документом. При нажатии на нее, появится запрос с просьбой скачать и установить плагин OCR. Выполните эти действия.
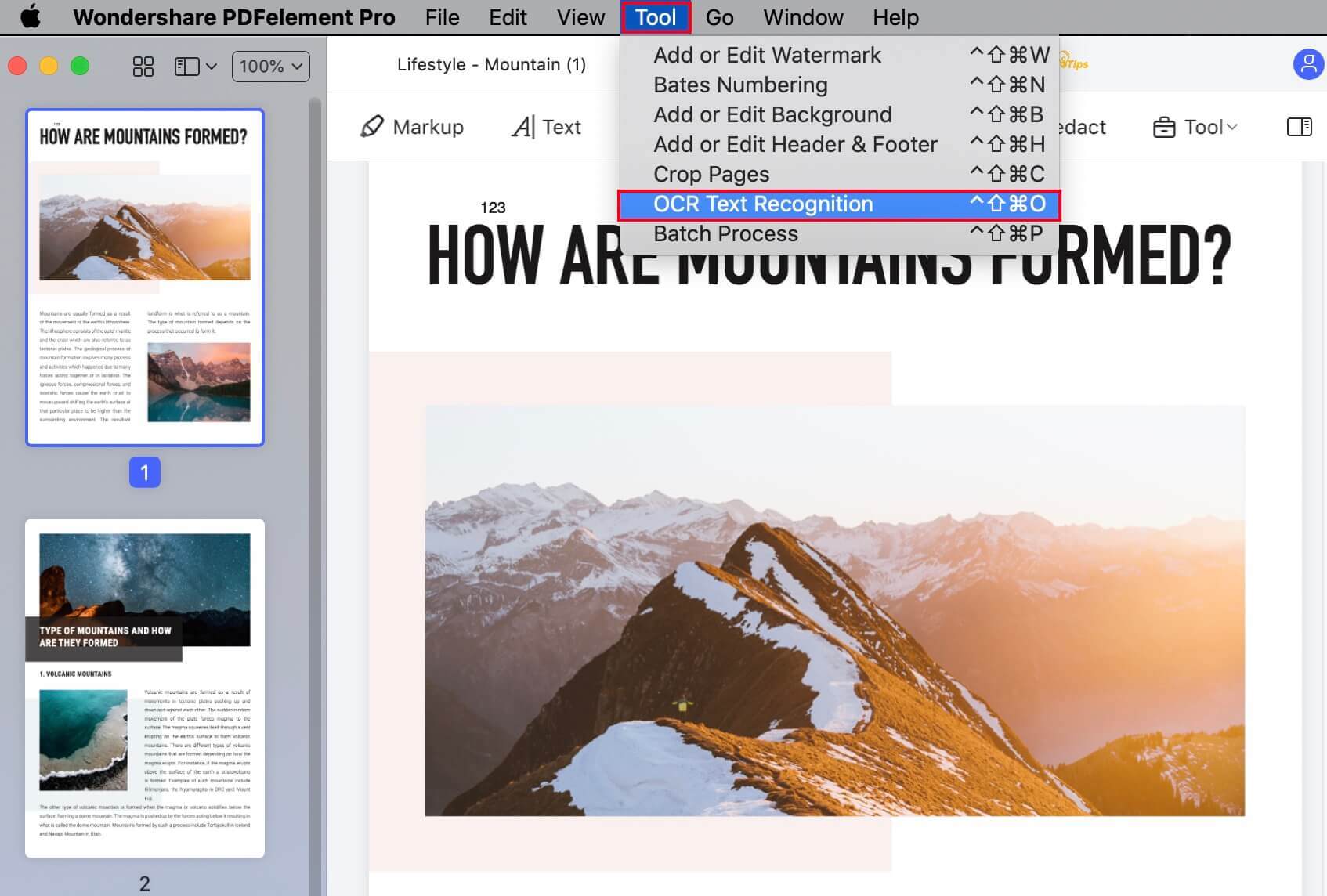
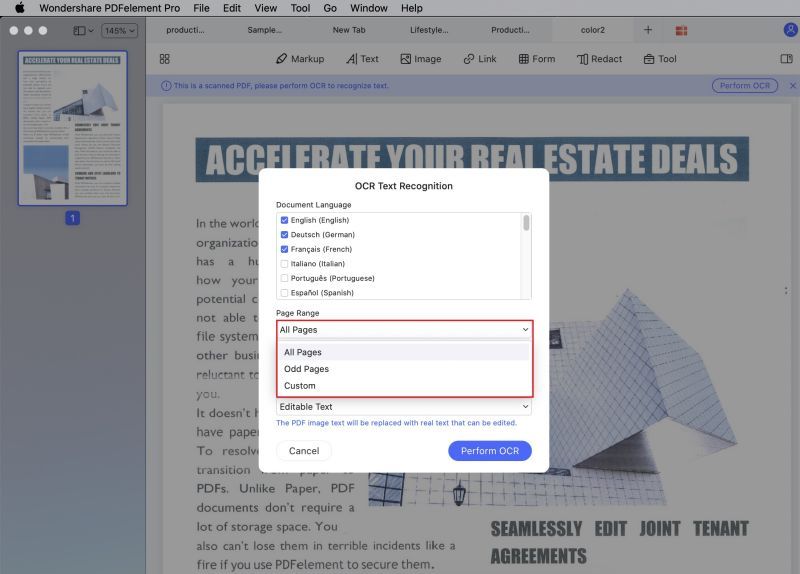
3. После установки, программа будет готова к оптическому распознаванию текста PDF файла. Нажмите кнопку уведомления, чтобы выполнить распознавание текста. На этот раз Вы увидите другое окно с двумя разделами параметров: в разделе «Параметры сканирования» выберите между редактируемым и доступным для поиска; в разделе «Диапазон страниц» выберите «Все», «Текущие» или укажите диапазон номеров страниц, которые необходимо преобразовать. Наконец, выберите исходный язык и нажмите Применить.
4. Теперь Ваш файл будет преобразован в соответствии с Вашими настройками.
Часть 2. Как Извлечь Оптически Распознанный Конвертированный Документ
Теперь, когда файл доступен для чтения или поиска, Вы можете редактировать его, извлекать текст и выполнять несколько других действий. Но как его экспортировать? Мы расскажем об этом далее.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
1. Поскольку теперь это файл PDF, дальнейшее преобразование не требуется. Вы можете экспортировать файл, перейдя в Файл→Сохранить как. Мы используем эту опцию, чтобы сохранить исходный PDF файл на основе изображений и использовать другое имя для преобразованного файла.
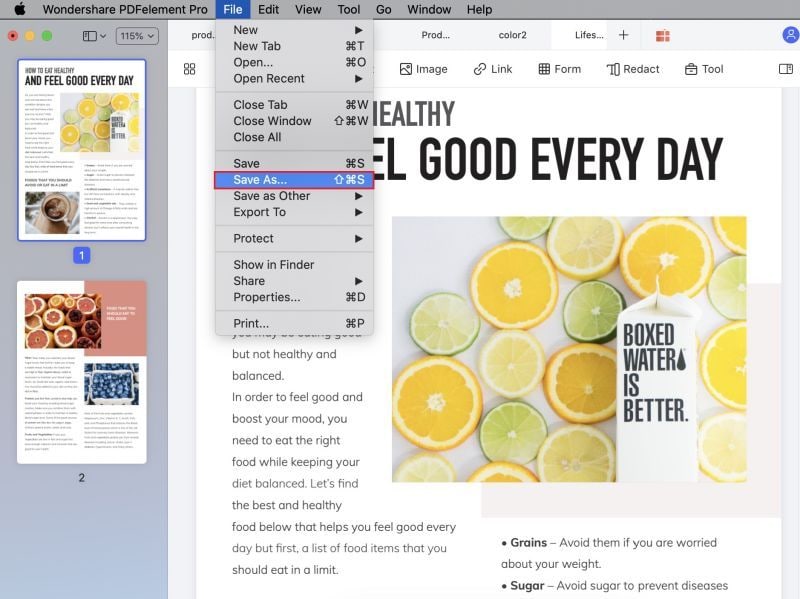
2. Если Вам нужно напрямую поделиться им по электронной почте или загрузить в облачное хранилище, Вы можете использовать значок «Поделиться» вверху или использовать «Файл»→«Поделиться», чтобы получить доступ к этой функции. Это действие запустит Ваш почтовый клиент по умолчанию или Ваш браузер. Вы можете заполнить остальные поля электронной почты или войти в свою учетную запись облачного хранилища и сохранить там PDF файл.
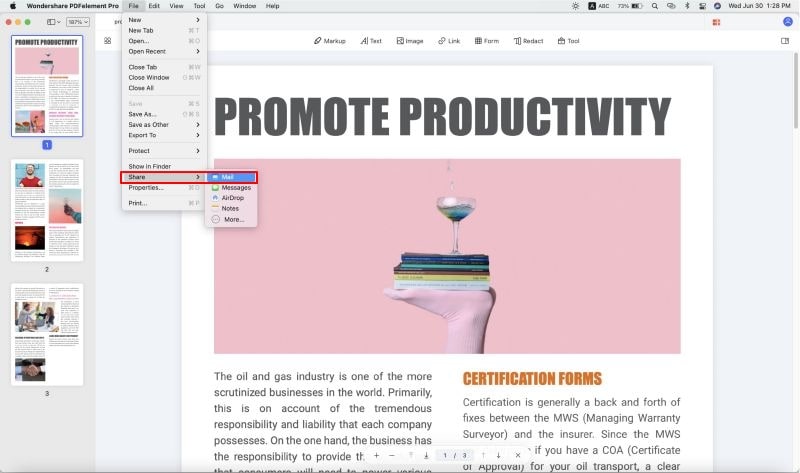
3. Еще один способ экспортировать PDF файл с оптическим распознаванием текста - распечатать его. Используйте для этого команду Файл→Печать.
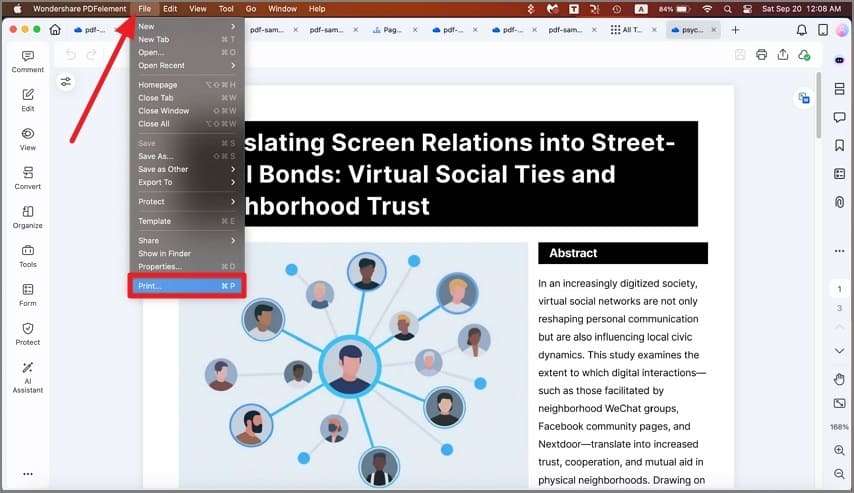
Теперь Вы можете выполнить эти два процесса для любого PDF файла на основе изображения или файла изображения, содержащего текст. Но как обрабатывать несколько файлов одновременно? PDFelement Pro также позволяет это делать, как описано в следующем разделе.
Часть 3. Как Извлечь Сразу Несколько Оптически Распознанных Документа
PDFelement Pro также предлагает функцию пакетной обработки для распознавания текста и многие другие функции. Чтобы использовать эту функцию, следуйте нашим инструкциям.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
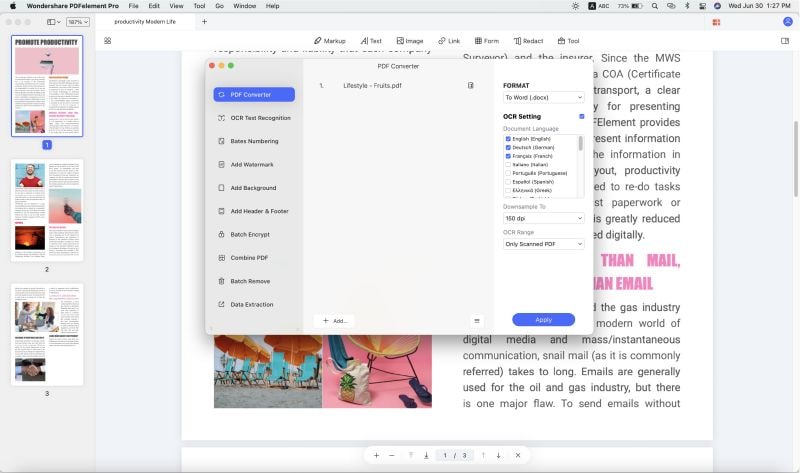
1. На вкладке «Инструмент» Вы увидите параметр «Пакетная обработка» на панели инструментов. Щелкните на него, чтобы открыть диалоговое окно пакетной обработки.
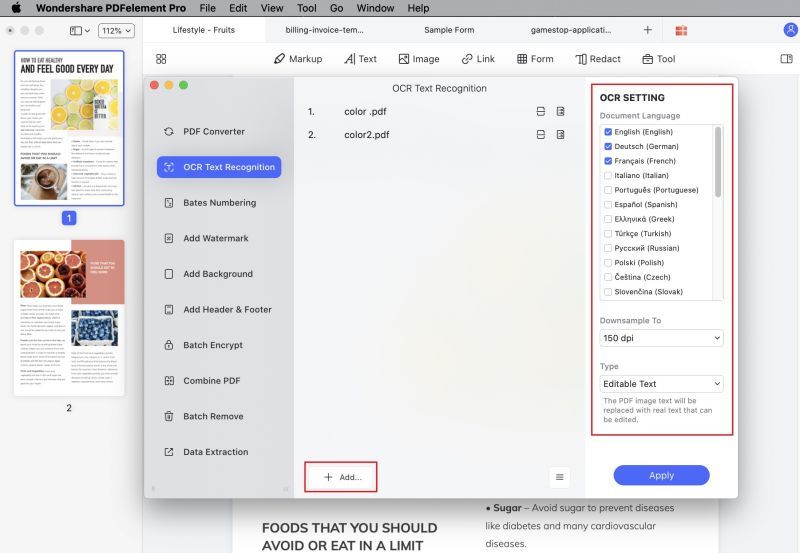
2. Слева Вы увидите различные параметры, такие как «Преобразовать», «Создать» и «Оптимизировать». Щелкните на OCR на боковой панели.
3. Вы можете перетащить файлы в это окно или использовать кнопку «Добавить файлы» в правом верхнем углу.
4. После того, как Ваши файлы были импортированы, Вы можете выбрать язык, диапазон страниц и другие параметры, такие как возможность поиска/редактирования. По завершении, нажмите «Применить», и все файлы будут преобразованы в соответствии с указанными Вами настройками.
Используя этот процесс, Вы можете мгновенно преобразовать сотни файлов с помощью функции OCR, что позволит Вам быстро оцифровать рабочие документы.
Часть 4. Как Редактировать Отсканированные Документы с Помощью OCR
После того, как оптическое распознавание было выполнено и файл стал доступным для редактирования, Вы можете редактировать его так же, как любой другой файл PDF. Это означает, что Вы можете контролировать каждый элемент в файле, будь то текст, изображения, гиперссылки, встроенные объекты, водяные знаки, верхние/нижние колонтитулы и т.д. Вот процесс редактирования отсканированного документа после распознавания текста.
1. Предполагаем, что Вы уже выполнили оптическое распознавание, поэтому теперь Вы можете перейти на вкладку «Редактировать» вверху.
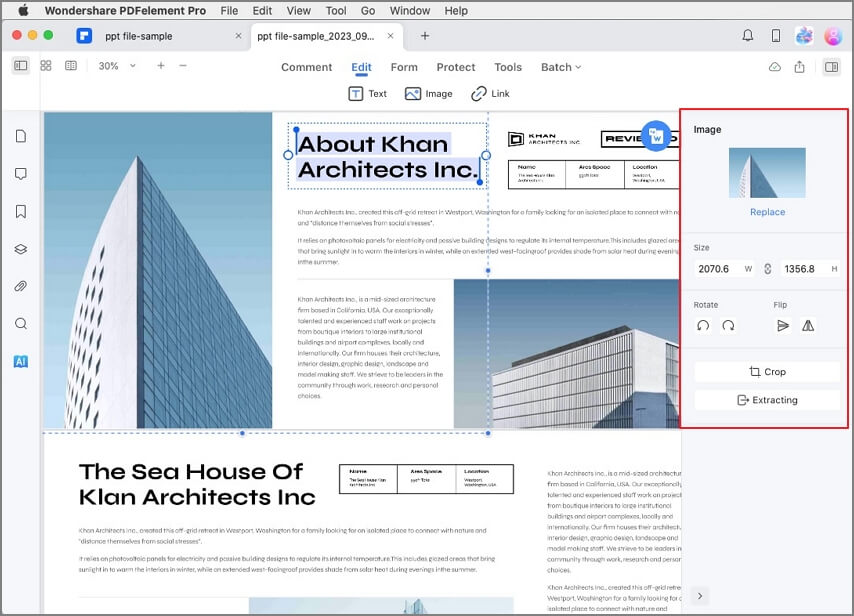
2. Это отобразит различные инструменты редактирования для различных компонентов. Например, если Вы хотите отредактировать фрагмент текста, нажмите на значок «Текст». Вы также можете редактировать текст в режиме строки или абзаца.
3. Находясь в режиме редактирования текста, Вы можете выбрать любое слово, фразу, предложение или абзац в документе и либо удалить его, либо что-то добавить, либо изменить его.
4. Чтобы редактировать изображения, просто нажмите на значок изображения и выберите изображение. У Вас будет возможность заменить, повернуть, изменить положение и т.д.
5. Точно так же есть варианты добавления или редактирования ссылок, водяных знаков, фона и многого другого.
Почему PDFelement?
В заключение, давайте попробуем ответить на этот очень важный вопрос. Причина, по которой это важно, заключается в том, что Вы можете использовать другой редактор PDF с функцией распознавания текста, но он может быть неточным или выходить за рамки Вашего бюджета. Вот некоторые из причин, по которым стоит подумать о переходе на PDFelement:
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
- Точный - Высокоточное распознавание текста на более чем 20 языках с поддержкой многоязычного распознавания текста
- Быстрый - Скорость преобразования - одна из лучших в отрасли
- Интуитивно понятный - Новым пользователям не нужно обучаться работать с PDFelement, что упрощает переход на эту программу
- Обширный - В PDFelement можно найти почти все функции самых известных в мире редакторов PDF
- Обновляемый - PDFelement получает постоянные обновления версий, как второстепенные, так и основные, которые позволяют достигать новых показателей производительности и взаимодействия с пользователем.
Наконец, давайте попробуем ответить на некоторые вопросы, которые могут у Вас возникнуть по оптическому распознаванию текста и связанным темам.
Часто Задаваемые Вопросы
На 100% ли точное распознавание текста?
Ни один инструмент распознавания текста не обеспечивает 100% точности для всех типов текстового содержимого. Например, если текст написан от руки и плохо читается, его очень трудно прочитать человеку, не говоря уже о распознавании текста. Однако для печатного текста распознавание текста максимально точное. Таким образом, он чрезвычайно полезен при преобразовании отсканированных файлов, содержащих печатный текст и другие символы.
Могу ли я использовать OCR для рукописных заметок?
Как уже упоминалось, почерк должен быть разборчивым, чтобы функция распознавания текста работала точно. Курсивное письмо преобразовать труднее всего, но уровень точности намного выше, если почерк понятен. Помните, что чем четче текст и чем он удобнее для человеческого глаза, тем точнее распознается текст.
Могу ли я напрямую сканировать документ в редактируемый PDF файл?
Да, PDFelement предлагает эту функцию. Чтобы использовать ее, Вы можете нажать Файл→Создать→Со сканера. Откроется диалоговое окно настроек сканирования, в котором Вы увидите кнопку «Сканировать». Щелкните по нему, и сканер отсканирует документ, после чего PDFelement импортирует его и преобразует с помощью плагина OCR.





