
OCR или оптическое распознавание символов - это процесс идентификации текста и других символов в файле на основе изображения и преобразования его в форму, которая доступна для машинного редактирования или электронного поиска. OCR, также известное как распознавание текста, является очень ценным коммерческим инструментом. Компании используют его для оцифровки и архивирования важных документов. Школы используют его для преобразования физического контента в цифровой контент. Использовать его могут даже частные лица - для преобразования своих квитанций, счетов, счетов-фактур и других документов в электронные форматы для различных целей, например для подачи налоговой декларации онлайн и т.д.
- Часть 1. Обзор OCR
- Часть 2. Как преобразовать PDF-файл, состоящий из изображения, в PDF с возможностью поиска
- Часть 3. Как узнать, что PDF-файл недоступен (для редактирования или поиска)
- Часть 4. Каковы преимущества PDF-файлов с возможность редактирования и поиска
- Часть 5. Почему следует выбрать PDFelement Pro для распознавания PDF-файлов
Часть 1. Обзор OCR
Универсальность OCR
- OCR доступен на нескольких языках. Например, Wondershare Wondershare PDFelement - Редактор PDF-файлов Pro теперь поддерживает более 20 различных языков и даже может преобразовывать двуязычный или многоязычный текст в редактируемые PDF-файлы, поддерживающие внутренний поиск.
- Вы также можете выбрать диапазон страниц, который вы хотите преобразовать, если вам не нужно распознавать весь документ.
- Кроме того, у вас есть выбор: выбрать язык самостоятельно или разрешить программе определить его (в случае, если в тексте присутствует более одного языка).
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Как улучшить результаты распознавания текста
Поскольку распознавание текста срабатывает не всегда на 100% точно при любых условиях, перед распознаванием отсканированного PDF-файла или файла изображения, содержащего текст, лучше следовать некоторым общим правилам:
Текст должен быть читаемым человеческим глазом - Если вы можете четко прочитать документ, вы получите гораздо лучшие результаты распознавания текста. Документы, отсканированные с мятой бумаги, или расплывчатые изображения дают плохие результаты.
Документ должен быть среднего или высокого разрешения - Текст с низким разрешением приводит к плохим результатам распознавания текста, поэтому убедитесь, чтобы у используемых изображений было подходящее разрешение. Вы можете использовать инструмент экстраполяции изображений, чтобы увеличить разрешение или dpi. Это даст вам больше шансов получить точные результаты распознавания текста.
Уберите шум в документе - Если в тексте присутствуют другие бессмысленные символы, механизму распознавания текста будет труднее отделить фактические символы от случайных форм. Используйте инструмент понижения уровня шума для уменьшения шума изображения и увеличения контрастности текста, и вы получите более точный результат.
Горизонтальный текст лучше наклонного - Механизмы OCR работают, анализируя документ горизонтально сверху вниз. Если текст расположен вертикально или сдвинут, его сложнее будет преобразовать. Поэтому убедитесь в том, что вы не исказили текст, прежде чем запускать его распознавание.
Продвинутое распознавание текста работает не только с символами
Простые программы OCR предназначены для работы с простым текстовым содержимым. Однако более продвинутые, такие как плагин OCR, используемый в PDFelement Pro, могут идентифицировать специальные символы, математические операции, химические формулы и различные другие символы. Функция определения языка - это отличный пример того, насколько данная программа мощная и эффективная. Если у вас есть документ, содержащий сочетание текста, специальных символов, формул и другой разрозненной информации, которую нужно преобразовать в PDF-файлы с возможностью редактирования или поиска, PDFelement Pro - это лучший вариант для оптического распознавания такого PDF.
Часть 2. Как преобразовать PDF-файл, состоящий из изображения, в PDF с возможностью поиска
Благодаря интеллектуальному коду, лежащему в основе интуитивно понятного пользовательского интерфейса программы PDFelement, выполнение OCR документа в ней - это очень простой процесс. Когда вы открываете PDF-файл, который был отсканирован из физического документа или изображения с текстом, преобразованным в PDF, программа автоматически распознает это и спросит вас, хотите ли вы сначала скачать и установить плагин OCR. Затем она предложит вам установить плагин и выполнить оптическое распознавание. Давайте посмотрим, как это сделать шаг за шагом:
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
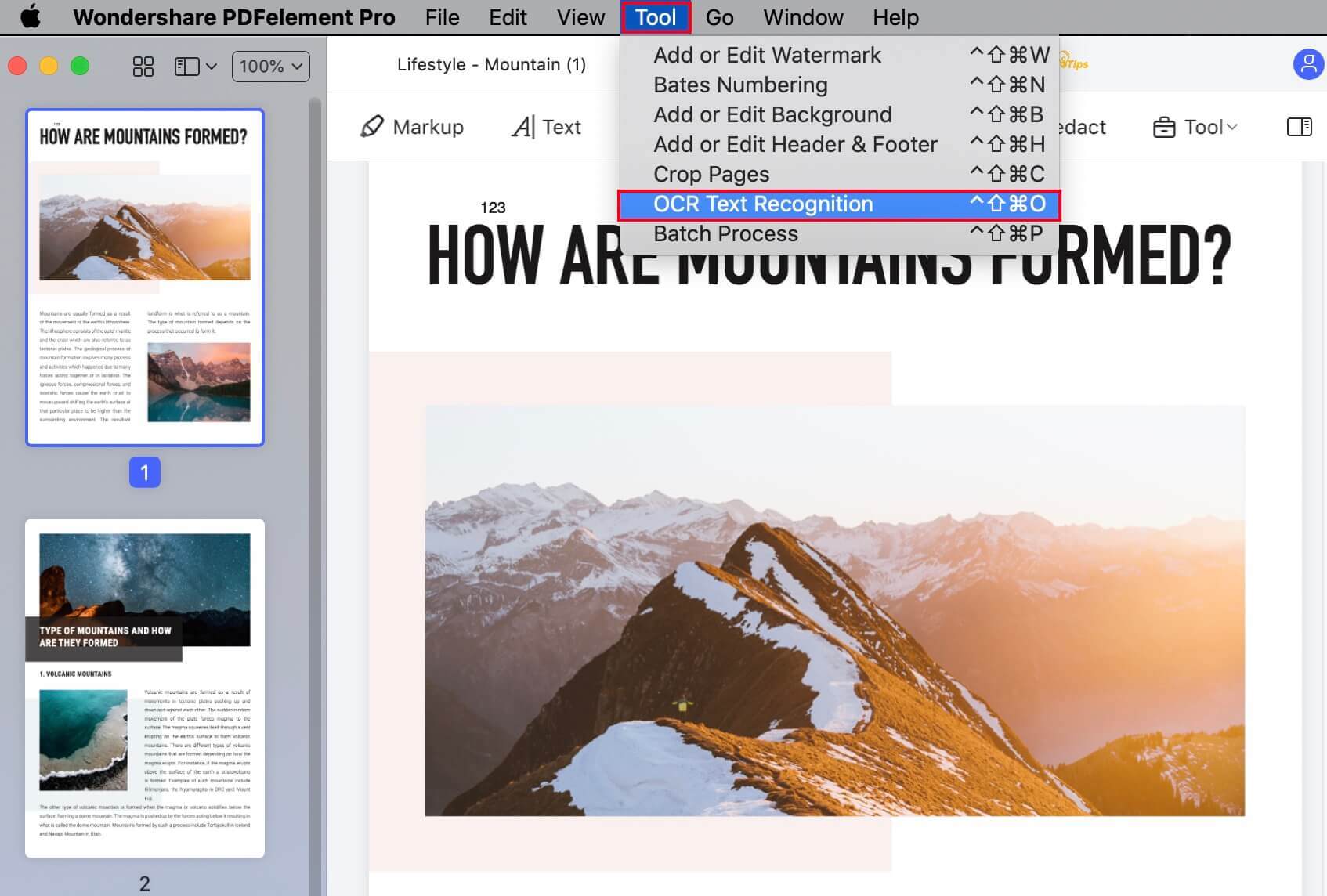
1. Чтобы установить плагин вручную, перейдите в Инструменты → Оптическое распознавание текста или же перейдите в PDFelement → Настройки → Плагин → Установить.
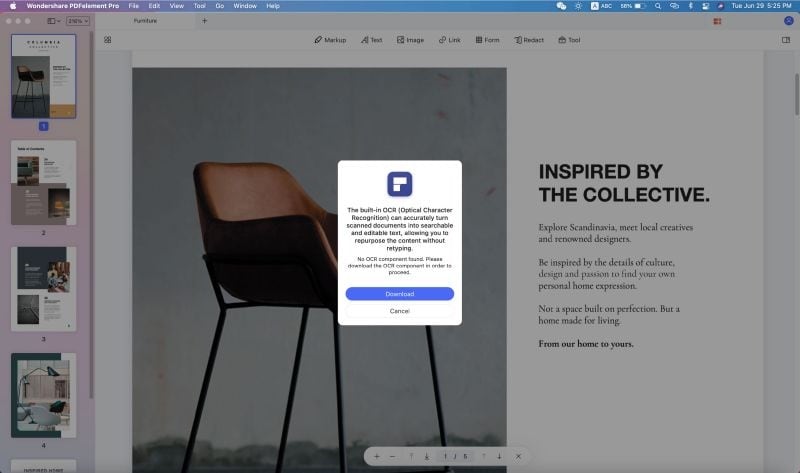
2. Открывая PDF-файл, который нельзя редактировать, вы увидите панель уведомлений и подсказку с надписью "Выполнить распознавание текста" над окном просмотра документа. Щелкните по этой опции.
3. В небольшом всплывающем окне выберите диапазон страниц, который нужно преобразовать. Доступны следующие варианты: "Все", "Нечетные страницы", "Четные страницы" и "Пользовательский", что дает вам возможность выбрать именно те страницы, которые вам нужны. Нажмите ОК, чтобы продолжить.
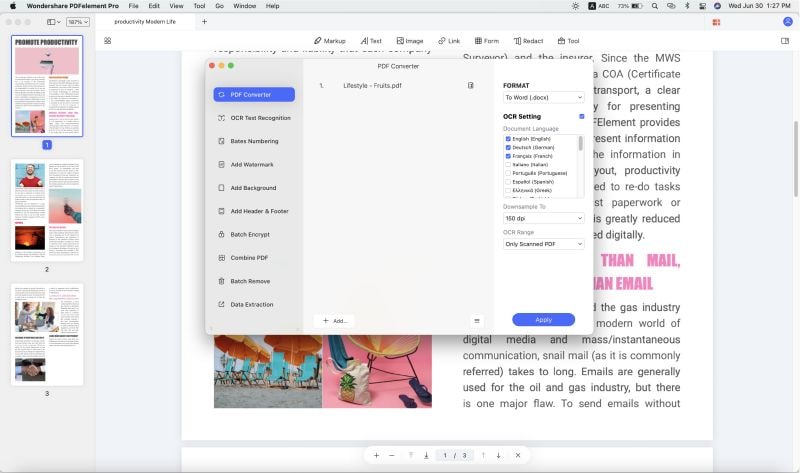
4. В окне настройки распознавания текста выберите язык, разрешение пониженной дискретизации, а также, хотите ли вы, чтобы преобразованный текст был доступен для редактирования или поиска.
5. Нажмите "Выполнить распознавание текста", и файл будет преобразован и отображен в программе. Теперь вы можете отредактировать файл или выполнить в нем поиск желаемого текста (в зависимости от того, какой вариант вы выбрали на предыдущем шаге).
Если у вас есть несколько документов, в которых необходимо выполнить OCR, вы можете использовать для этого процесс пакетного OCR.
1. Перейдите в Инструменты → Пакетная обработка.
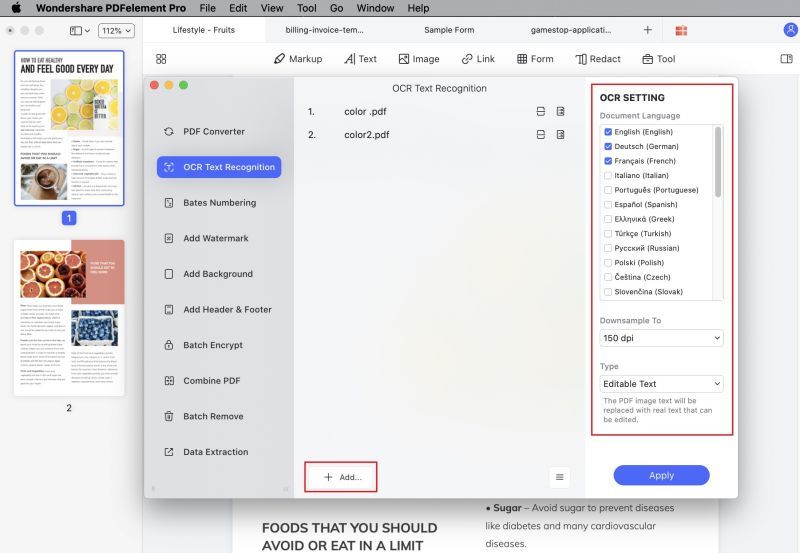
2. В окне пакетной обработки выберите вкладку оптического распознавания текста (OCR) на левой боковой панели.
3. Теперь перетащите файлы или воспользуйтесь кнопкой "Добавить файлы" внизу, чтобы импортировать несколько отсканированных документов.
4. На правой боковой панели выберите настройки распознавания текста, как было описано ранее.
5. Нажмите "Применить", чтобы выполнить распознавание всех этих документов.
После завершения преобразования документа или документов вы можете сохранить их под другим именем файла, чтобы указать, доступны ли они для редактирования или поиска. Исходные файлы останутся без изменений.
Часть 3. Как узнать, что PDF-файл недоступен (для редактирования или поиска)
Когда вы открываете PDF-файл в PDFelement, программа автоматически отсканирует документ и подготовит его к редактированию и другим задачам. Так, программа обычно распознает отсканированный текст и предупредит вас с помощью уведомления, упомянутого выше. Если вы пропустите это сообщение, вы с легкостью сможете самостоятельно определить, доступен ли документ или нет.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
1. Попробуйте отредактировать фрагмент текста, щелкнув по опции "Текст" на левой боковой панели и выбрав любой текст в документе. Если вы не можете выделить его, значит, текст нельзя редактировать.
2. После этого попробуйте найти текст, который вы видите в документе, с помощью команды Cmd + F.
3. Затем попробуйте использовать функцию редактирования изображения, щелкнув по изображению слева и выбрав изображение.
Если вы не можете выполнить какое-либо из вышеперечисленных действий, это означает, что ваш PDF-файл не доступен для чтения, редактирования или поиска.
Часть 4. Каковы преимущества PDF-файлов с возможность редактирования и поиска
Все мы знаем, что функция OCR очень важна для работы с PDF-документами. Но почему же? Почему нельзя оставить файлы PDF с изображениями или отсканированные PDF-файлы без изменений? Причин для этого много:
- В этих файлах нельзя выполнять поиск содержимого, что представляет серьезную проблему для очень больших файлов.
- Их нельзя преобразовать в другие редактируемые форматы, такие как Word, Excel и т.д.
- Очевидно, что их нельзя каким-либо образом редактировать, поэтому, если информация внутри становится устаревшей и неактуальной, сам файл становится бесполезным, если у вас нет способа обновить информацию в нем.
- Из файла нельзя извлечь изображения, если вы не используете обходной путь, например, делаете скриншоты. Если вы дизайнер, то знаете, что это не лучший способ работы.
Точно так же есть несколько других причин, по которым OCR является важной частью документооборота. PDF-файлы со специальными возможностями легче архивировать, искать, редактировать, конвертировать и выполнять различные другие задачи по работе с PDF, которые невозможно выполнить с нечитаемым файлом.
Часть 5. Почему следует выбрать PDFelement Pro для распознавания PDF-файлов
PDFelement Pro использует мощный и надежный движок ABBYY® FineReader® Engine 11 для преобразования файлов на основе изображений в редактируемые PDF-файлы. Этот механизм OCR является одним из самых популярных приложений в этой категории и известен своей точностью, скоростью и способностью обрабатывать большие объемы данных (пакетный процесс) за короткое время.
Кроме того, сам PDFelement предлагает превосходный интерфейс для взаимодействия с такими файлами до и после преобразования. Перед преобразованием их с помощью OCR их можно упорядочить путем удаления или добавления страниц, объединения файлов, удаления водяных знаков и т.д. После преобразования с помощью OCR PDFelement позволяет выполнять множество других операций, таких как преобразование, защита, заполнение форм, добавление электронной подписи, оптимизация размера файла и несколько других важных задач.
И самое главное: PDFelement Pro - это одно из самых доступных решений по работе с PDF на рынке с таким впечатляющим набором важных функций, интуитивно понятным пользовательским интерфейсом, удобной навигацией, полезными процессами и быстрым процессом обучения.
Частые вопросы (ЧЗВ)
Может ли OCR преобразовать рукописный текст?
Да, OCR сможет достаточно хорошо считать рукописный текст, если почерк разборчивый и четкий (не выцветший), а бумага перед сканированием не была смята и сморщена. Конечно, результат будет не настолько точным, что и при выполнении OCR печатного текста, но в определенной степени это действительно возможно.
Могу ли я напрямую создать редактируемый PDF-файл со сканера?
Да, в меню PDFelement есть пункт "Файл" → "Новый" → "PDF со сканера", который можно использовать для этой функции. Все, что вам нужно сделать, это подключить свой сканер к тому же компьютеру, на котором запущен PDFelement Pro, нажать на этот пункт меню для запуска процесса и следовать показанным шагам. Вы можете сделать отсканированный документ доступным для редактирования или поиска.
Предусмотрена ли в PDFelement Pro дополнительная плата за функцию OCR?
Нет, плагин оптического распознавания текста включен в PDFelement Pro. Однако его необходимо загрузить и установить отдельно, как показано выше. Это связано с его очень большим размером, что повлияет на время загрузки и установки самого PDFelement, если включить его в установочный файл.





