100% Безопасно | Без рекламы |
100% Безопасно | Без рекламы |
Как мы можем извлекать изображения из PDF с помощью Python?
В некоторых файлах PDF есть изображения, которые мы хотели бы извлечь и использовать в качестве справочных материалов или включить в другие работы или проекты, которые вы выполняете. В таком случае вам придется искать способ извлечь изображения и сохранить их в предпочтительном формате. Продолжайте читать эту статью, чтобы узнать, как Python может эффективно извлекать изображения из файлов PDF.
Как извлекать изображения из PDF с помощью Python
Язык программирования Python очень удобен, когда вы хотите извлечь изображения из файлов PDF. Изображения могут быть любого формата в зависимости от выходных данных, которые вы пишете в коде. Кроме того, с помощью Python различные библиотеки могут позволить вам извлекать изображения из файлов PDF. Вот шаги по извлечению изображений из PDF с помощью Python.
- Шаг 1. В этом случае вам потребуются установленные на вашем компьютере библиотеки PyPDF2 и Pillow.
- Шаг 2. Затем откройте язык программирования, который вы используете, например Anaconda, и откройте Jupiter Lab.
- Шаг 3. После этого напишите следующий код, опубликованный на Stack Overflow.

В качестве альтернативы вы можете использовать модуль PyMuPDF, который будет извлекать изображения из PDF с помощью Python в формате PNG. Вот код для этого:

Как извлекать изображения из PDF без Python
Работа с Python для извлечения изображений из PDF требует знание языка программирования Python, понимание строк кода или скриптов. В противном случае описанный выше метод будет для вас бесполезен. Однако, если вы хотите получать изображения из файлов PDF без Python, вам необходимо использовать средство извлечения изображений PDF, например Wondershare PDFelement - Редактор PDF-файлов. Это программа для работы с PDF, совместимая с операционными системами Windows и Mac. Это программное обеспечение позволяет открывать файлы PDF, просматривать файлы PDF и извлекать изображения из файлов PDF. Более того, вы можете извлекать изображения из файлов PDF и сохранять их в различных форматах изображений, таких как PNG, JPEG, GIF, BMP и TIFF.
- Его пользовательский интерфейс хорошо спроектирован, так как вы можете легко перемещаться, прокручивать и находить меню и значки.
- Создает PDF-файлы из снимков экрана, изображений, существующих PDF-файлов и файлов других форматов.
- Встроенный редактор позволяет изменять тексты PDF, изображения, объекты и ссылки. Вы также можете добавлять водяные знаки, изменять фон, добавлять биты и нумерацию, а также верхние и нижние колонтитулы.
- Он интегрирован с технологией OCR, которая сканирует один или несколько файлов изображений и делает их редактируемыми.
- Он конвертирует файлы PDF в такие форматы, как HTML, PowerPoint, Excel, Texts, EPUB, Word и изображения.
- Аннотирует PDF-файлы с помощью текстовых полей, комментариев, штампов и рисунков.
- Позволяет создавать формы PDF, заполнять формы PDF и извлекать данные из форм PDF.
- Защищает файлы PDF с помощью паролей, разрешений и цифровых подписей. Вы также можете редактировать подписи или удалить их навсегда.
Вот пошаговое руководство по извлечению изображений из PDF с помощью PDFelement.
Шаг 1. Войдите в режим «Редактировать».
Начните с открытия приложения на вашем компьютере и нажмите «Открыть файлы», чтобы загрузить файл PDF. Как только вы откроете PDF-файл в программе, активируйте режим редактирования, щелкнув меню «Редактировать», а затем переключитесь в режим «Редактировать».
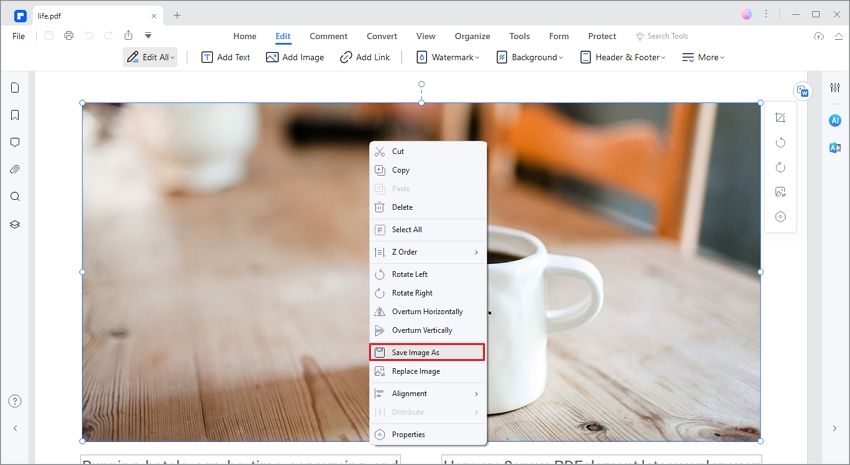
Шаг 2. Извлечение изображений из PDF без Python
Затем перейдите к изображению, которое вы хотите извлечь без кода Python, и щелкните его правой кнопкой мыши. Вы увидите списки параметров, которые появятся в раскрывающемся меню. В меню выберите опцию «Извлечь изображение».
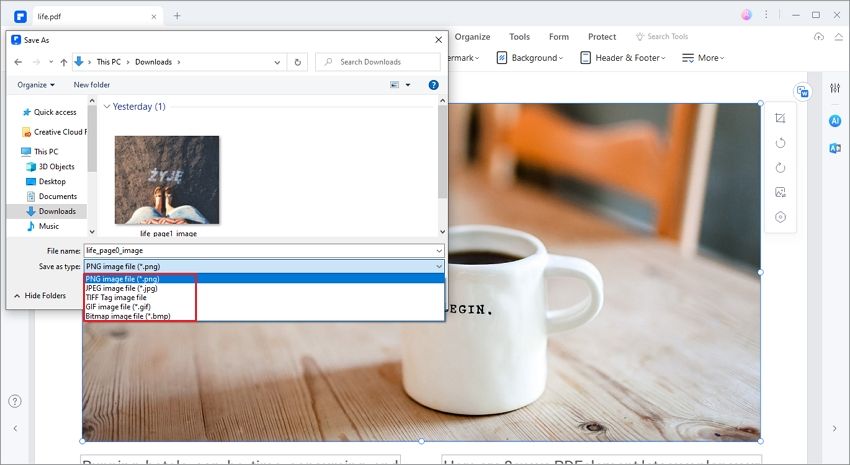
Шаг 3. Сохраните извлеченное изображение.
После этого появится окно сохранения. Щелкните «Сохранить как», чтобы выбрать выходной формат изображения, например .png, .jpeg, .bmp, .gif или .tiff. В опции «Имя файла» вы можете назвать свое изображение и затем нажать «Сохранить». Таким образом вы извлечете изображения из PDF без Python.