
Если у вас есть изображения или PDF-документ с примечанием и вы хотите извлечь или скопировать текст из изображений или PDF-файлов, не вводя его вручную, вы можете использовать OneNote OCR для этого. OneNote OCR, или так называемая облачная служба оптического распознавания символов Microsoft, может выполнить эту работу в кратчайшие сроки. Microsoft OneNote OCR довольно прост в использовании и требует всего нескольких шагов. Здесь мы приведем руководство о том, как скопировать текст с помощью OneNote Wondershare PDFelement - Редактор PDF-файловOCR и функции распознавания текста.
Как копировать текст с изображений с помощью OneNote OCR
- Шаг 1. Запустите Microsoft OneNote, импортируйте файл изображения в это программное обеспечение, прежде чем вы сможете начать использовать OCR в OneNote.
- Шаг 2: Щелкните правой кнопкой мыши на изображении. Вы должны увидеть опцию «Копировать текст с картинки». Как только вы нажмете на это, фрагменты текста будут скопированы в буфер обмена. Затем его можно вставить в другое приложение, например Word или Notepad.
- Шаг 3: Если изображений несколько, нажмите «Копировать текст со всех страниц распечатки», чтобы скопировать весь текст, а затем снова вставьте его в файл Word или Notepad.
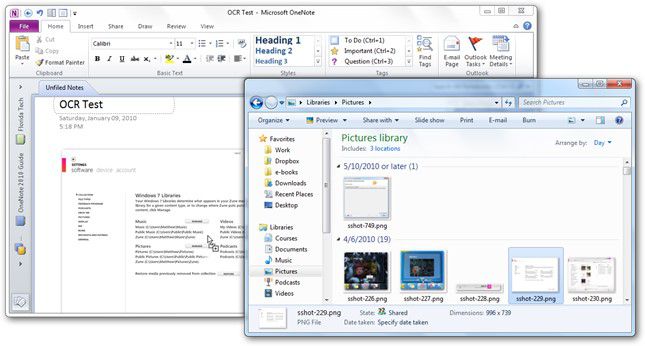
Вот, по сути, и все, что нужно сделать. Независимо от того, используете ли вы OneNote OCR для Mac или Windows, вы сможете легко выполнить этот процесс. Далее давайте рассмотрим некоторые проблемы, с которыми вы можете столкнуться при выполнении этой процедуры.
Лучшая альтернатива OneNote OCR - Wondershare PDFelement - Редактор PDF-файлов
PDFelement — это мультиплатформенный PDF-редактор и, возможно, одна из лучших и самых доступных альтернатив вездесущему Adobe Acrobat DC Pro. Приятный для глаз интерфейс в сочетании с интуитивно понятной навигацией и панелями инструментов «появляться при необходимости» значительно улучшает пользовательский интерфейс. У вас есть доступ ко всем инструментам Adobe, и PDFelement во многих случаях работает лучше, чем в случае с OCR.
Давайте рассмотрим процесс извлечения текста из отсканированных PDF-файлов и изображений в PDFelement.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Шаг 1. Откройте документ
После загрузки и установки PDFelement откройте его, и вы увидите домашнюю страницу с различными опциями. Чтобы открыть отсканированный документ или файл изображения, нажмите «Открыть файл...», перейдите к нужному файлу и нажмите «Открыть» в Проводнике, чтобы импортировать документ.
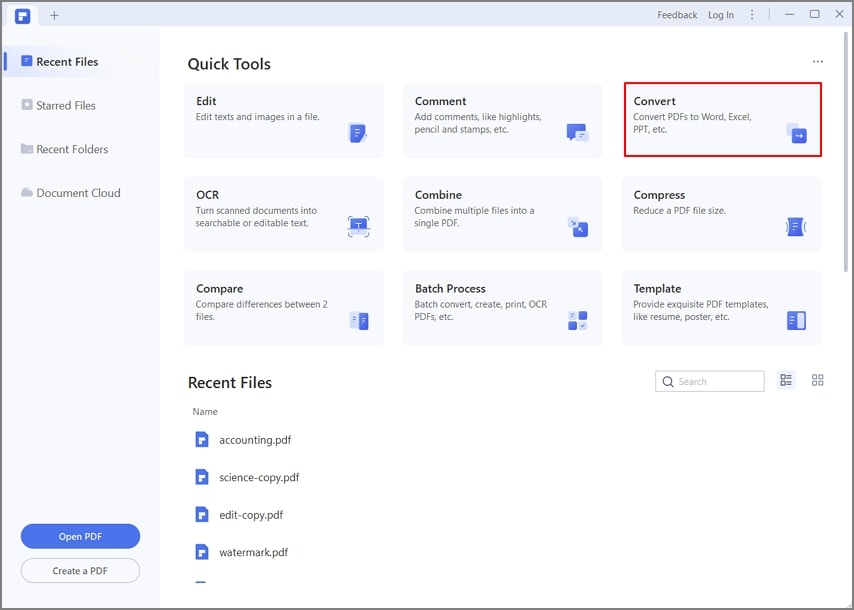
Шаг 2. Выполните распознавание текста
Когда документ открыт, нажмите «Конвертировать» в верхней строке меню, а затем выберите опцию «OCR» под ней. Программа автоматически обнаружит текст на изображении (или изображениях) и спросит, хотите ли вы выполнить распознавание текста. Нажмите на кнопку, чтобы сделать это.
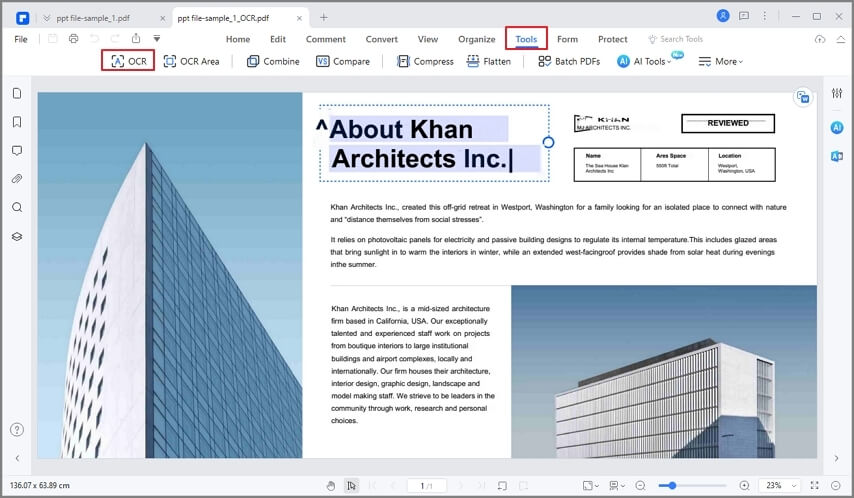
Шаг 3: Настройки для выполнения распознавания текста
После извлечения текста на изображении вы можете оставить его как «текстовое изображение с возможностью поиска» или сделать его «редактируемым текстом». Выберите второй вариант, затем выберите правильный язык и нажмите «ОК».
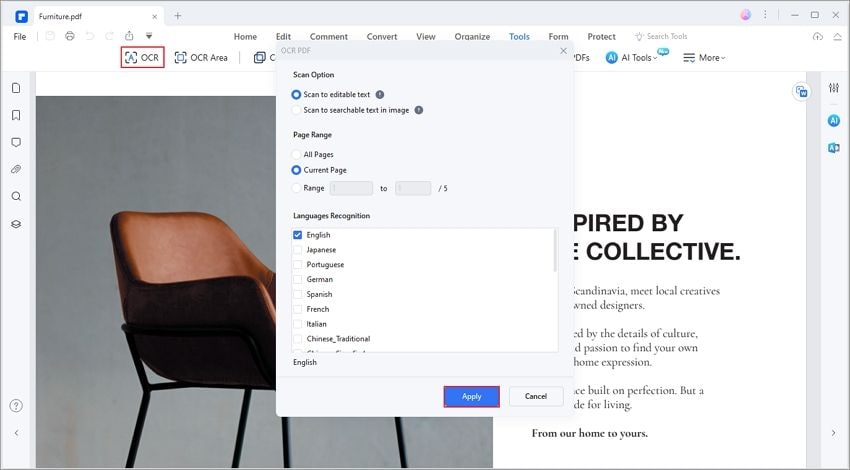
Шаг 4. Скопируйте текст из изображений
Когда процесс распознавания будет завершен, он отобразится в виде редактируемого текста. Нажмите вкладку «Редактировать» в верхнем окне, затем вы можете скопировать ее в другой документ или использовать в том же PDF-файле.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Вот насколько это просто, и этот инструмент намного точнее даже с рукописным текстом на изображениях и отсканированных PDF-файлах. Вот некоторые из ключевых функций OneNote OCR и PDFelement OCR по сравнению с другим инструментом распознавания текста в табличной форме.
Сравнение оптического распознавания текста OneNote и PDFelement OCR
|
Особенность
|
распознавание в onenote
|
Распознавание PDFelement
|
|---|---|---|
| Точность распознавания текста | Высокое | Высокое |
| Функция пакетного распознавания текста | Нет | Да |
| Вывод | Только текст | Текст, доступный для редактирования или поиска |
| Скорость работы утилиты распознавания текста | Допустимо | Высокоскоростное преобразование |
| Выдержка из рукописного изображения | Низкое качество | Лучшее качество |
| Обработка текста с несколькими столбцами | Допустимо | Хорошо |
Распространенные проблемы распознавания текста в OneNote и способы их устранения
Проблема № 1: Нет онлайн-доступности
Несмотря на то, что OneNote является облачным приложением, онлайн-распознавание текста невозможно. Другими словами, если вы попытаетесь щелкнуть правой кнопкой мыши на изображении в бесплатной онлайн-версии, вы не увидите возможности скопировать текст.
Исправление: Чтобы устранить эту проблему, вам необходимо загрузить OneNote для macOS или Windows 10 (предпочтительнее). Вы даже можете сделать это на Android или iOS. После загрузки соответствующей версии вы увидите возможность извлечения текста из изображений или PDF-файлов.
Проблема № 2: Недоступен для немедленного извлечения
Это означает, что при нажатии правой кнопки мыши на изображении в настольной версии OneNote вы можете не сразу увидеть возможность копирования текста. Одна из причин, по которой это может произойти, заключается в том, что OneNote все еще обрабатывает данные на изображении.
Исправление: Единственное, что вы можете сделать на данном этапе, - это подождать, пока изображение или картинки не будут полностью отсканированы и доступны для извлечения текста.
Проблема № 3: Не подходит для рукописного текста
Распознавание текста прекрасно работает с изображениями печатного текста, но не так хорошо с материалами, написанными от руки. При наличии рукописных заметок извлеченный текст, скорее всего, будет содержать множество опечаток, поскольку они не были должным образом распознаны инструментом распознавания текста.
Исправление: К сожалению, реального решения этой проблемы не существует. Вы можете попробовать извлечь изображение несколько раз, но это может не сработать должным образом, поскольку распознавание текста OneNote выполняется с точностью только в 90% случаев, даже при использовании печатного текста на изображениях или отсканированных PDF-файлах. Лучше попробовать профессиональную утилиту для распознавания текста, подобную той, которая представлена в следующем разделе.





