
За последние несколько десятилетий технология PDF значительно продвинулась в области оцифровки архивов. То, что когда-то было сложной задачей для хранения данных и облегчения поиска, теперь стало обычным явлением. Одним из ключевых факторов, повлиявших на это изменение, является OCR или оптическое распознавание символов. Давайте посмотрим, почему OCR играет такую важную роль в оцифровке архивов, как оно применяется и как с помощью различных методов можно повысить точность распознавания.
 100% безопасно |
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
Часть 1. Применение OCR в оцифровке архивов
OCR - это, по сути, процесс распознавания, извлечения и встраивания текстового содержимого из цифрового или физического документа, созданного на основе изображений, в существующий слой изображения. Эта двухслойная технология поддерживается PDF, что делает его идеальным средством для оцифровки архивов. Есть несколько других причин, по которым PDF может считаться идеальным средством для оцифровки архивов документов.
1. Инновации в традиционных методологиях каталогизации и индексирования
Каталогизация и индексирование часто идут рука об руку, но это два совершенно разных процесса. Каталогизация - это организация активов или элементов контента, в то время как индексирование связано с поиском информации. Оба необходимы при архивировании документов, аудиовизуальных средств массовой информации, газет, журналов, академических журналов и других типов контента. Каталогизация помогает определить, что есть в наличии, а индексирование позволяет найти именно ту информацию, которую вы ищете.
Преобразование физических документов или отсканированных файлов в PDF позволяет одновременно каталогизировать и индексировать такие документы с помощью технологии OCR. Оцифрованный контент можно сделать доступным для редактирования или поиска, что позволяет упростить каталогизацию, а также индексацию архива. Таким образом, OCR - это фактически новый способ каталогизации и индексации архивов документов, что делает этот процесс доступным для компьютеров.
2. Реализация настоящего полнотекстового поиска
Ручное индексирование обычно страдает от человеческих ошибок, процент которых может составлять от 3% до 30% в зависимости от решаемой задачи. Это означает, что текстовые документы могут не индексироваться должным образом, если процесс выполняется вручную. То же самое и с каталогизацией, однако процент в этом случае будет меньше. Однако с помощью OCR преобразование можно выполнить с точностью от 98% до 99%. В свою очередь, это позволяет выполнять полнотекстовый поиск и извлечение. Когда эта возможность используется в тандеме с метаданными и элементами индексирования, это приводит к усовершенствованной системе каталогизации и индексирования.
3. Технология двухслойного PDF
Хотя в общем понимании OCR встраивает слой текста в существующее изображение, на самом деле он отображается как невидимый текст в PDF-файле. Однако теперь этот текст можно выделить и, следовательно, он становится доступен для поиска. В процессе оцифровки архива архивист сначала проверяет, соответствует ли оцифрованный текстовый слой тексту в исходном изображении. Этот этап проверки качества имеет решающее значение для точности отображаемого текста. Все изменения будут сохранены в копии файла с распознанным текстом, что упростит поиск по ключевым словам. Любые опечатки, пропущенные во время этой проверки качества, сделают документ недоступным для поиска по этому конкретному ключевому слову. Здесь важны слои. Это позволяет архиватору визуально проверять, соответствуют ли символы, распознанные механизмом распознавания текста, символам в исходном файле с изображением.
4. Расширение использования архивных файлов
Оптическое распознавание текста в PDF-документе отображает слой с возможностью поиска, но также может сделать текст доступным для редактирования. Однако для целей архивирования и поиска предпочтительнее использовать документ с активным внутренним поиском, поскольку информация индексирования может помочь в возврате результатов полнотекстового поиска. В свою очередь, это позволяет использовать документы с оптическим распознаванием текста в различных сценариях в зависимости от того, доступны ли они для редактирования или поиска. Например, гораздо проще исправить фрагмент текста в файле на основе изображения с помощью OCR, чем исправить тот же текст в инструменте редактирования изображений. OCR открывает ряд таких возможностей, с которыми не могут сравниться традиционные методы архивирования.
Часть 2. Как улучшить качество распознавания при OCR
Точность выполнения OCR зависит от многим моментов, связанных как с программным продуктом, так и с самим использованием. Все перечисленное ниже позволяет повысить точность OCR, при этом обеспечить желаемые условия можно до или после выполнения OCR.
1. Использование качественного программного обеспечения - PDFelement
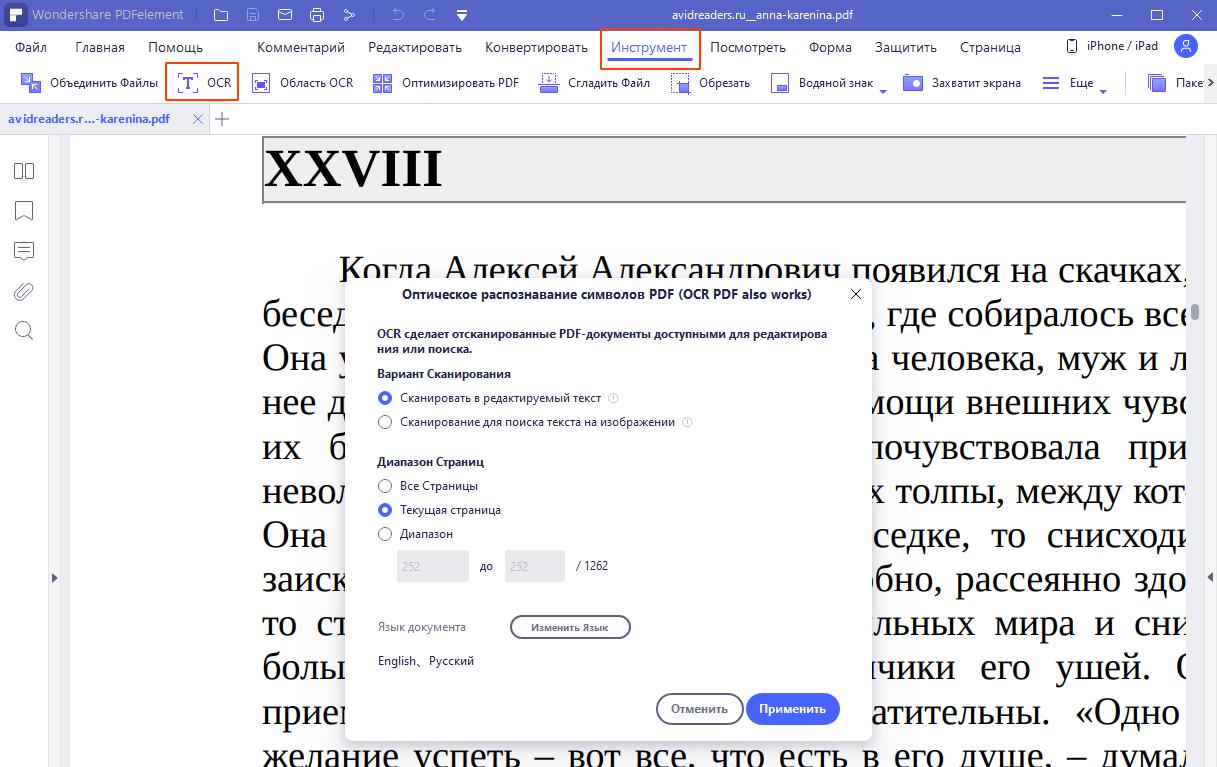
Плагин OCR в Wondershare PDFelement - Редактор PDF-файлов очень точен и даже может работать одновременно с несколькими языками. Кроме того, PDFelement предлагает преобразование как в доступные для поиска, так и в редактируемые версии исходного PDF-файла. Он также может напрямую создавать PDF-файлы, используя входные данные со сканера, а также преобразовывать нетекстовые форматы файлов в редактируемые/доступные для поиска PDF-файлы.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
2. Оптимальные параметры сканирования
При сканировании документов важно установить правильные параметры в настройках сканера. Главный из них - ориентация. Убедитесь, что документ подается в сканер под правильным углом, поскольку перекос листа может серьезно повлиять на точность распознавания текста.
3. Настройка разрешения
Лучшее разрешение для точного распознавания текста - 300 dpi или точек на дюйм. Такое разрешение обеспечивает "более плотное" сканирование, позволяя механизму оптического распознавания текста работать с удвоенным количеством контрольных точек по сравнению с обычными 150 dpi.
4. Выбор цветового режима
Для обесцвеченных или старых документов рекомендуется использовать цветовой режим RGB, чтобы сканер мог полностью захватить содержимое физического документа. Однако в целом сканирование в режиме оттенков серого является лучшим вариантом для обеспечения точности распознавания текста. Хотя черно-белый режим помогает сканировать изображение с большей скоростью, он может повлиять на качество распознавания текста.
5. Регулировка яркости и контрастности
Что касается яркости, оба проявления крайности - слишком высокая или слишком низкая - могут отрицательно повлиять на качество и точность распознавания текста. По этой причине рекомендуемая настройка яркости составляет 50%. Однако все также зависит от самого сканера, поэтому все нужно настраивать методом проб и ошибок.
В случае с контрастностью, обычно предпочтительнее использовать самые высокие настройки, потому что OCR, по сути, работает, анализируя темные и светлые области для идентификации отдельных символов. Затем применяются правила для сопоставления этих результатов с известными символами, текстом и числами. Если контраст между темной частью текста по сравнению с окружающими нетекстовыми частями будет высоким, результат OCR будет более точным.
6. Коррекция изображения и спецобработка
Эти два компонента сильно влияют на качество OCR. Коррекция изображения охватывает такие аспекты, как увеличение разрешения, применение цветовой коррекции и опробование различных настроек контрастности, в то время как спецобработка включает удаление нетекстовых символов, таких как значки, нетекстовые изображения, необычные символы и т.д. Оба эти действия чрезвычайно важны, поскольку они позволяют механизму OCR более точно "считывать" документ.
7. Тщательная вычитка
В зависимости от того, насколько точным будет конечный результат, может потребоваться (а может и нет) ручная вычитка. Если точность имеет для вас первостепенное значение, то это обязательный шаг в процессе оцифровки архива. По сути, он включает в себя ручную проверку оцифрованного текста человеком для того, чтобы убедиться, что отсканированные символы правильно распознаются в контексте отсканированного изображения. Это утомительный и кропотливый процесс, но во многих случаях он просто необходим.
PDFelement - Лучшая программа с функцией OCR для оцифровки архивов
PDFelement предлагает высокоточный механизм распознавания текста, но также дает несколько других преимуществ, когда дело доходит до оцифровки архивов. Вот некоторые из функций, которые делают его идеальным программным обеспечением для распознавания PDF-файлов и сканированных изображений.
100% безопасно |![]() Работает на основе ИИ
Работает на основе ИИ
- Возможности полного редактирования - После преобразования документа в редактируемый PDF-файл его можно легко изменить с помощью инструментов редактирования изображений, текста, таблиц, графиков, нижних и верхних колонтитулов, водяных знаков, гиперссылок и другого содержимого.
- Многоязычное OCR - Если у вас есть документ на нескольких языках, вы можете с уверенностью использовать PDFelement для процесса распознавания текста. Он поддерживает более 20 языков, что помогает повысить общую точность распознавания текста.
- Пакетная обработка - OCR может выполняться для целого пакета документов, что позволяет сэкономить время в процессе цифрового архивирования.
- Аннотации - Конвертированные файлы можно аннотировать с помощью примечаний, выделения и другого содержимого, что облегчает процесс индексации. Список аннотаций и макет с вкладками PDFelement упрощают перекрестные ссылки на тексты при исследовании определенной темы с использованием файлов с оптическим распознаванием текста.
- Электронная подпись и безопасность - Файлы можно подписывать с помощью цифровой или электронной подписи, а также защищать от несанкционированного просмотра или редактирования с помощью шифрования на основе пароля. Это помогает проверить подлинность документа и предотвращает внесение каких-либо изменений. Обезличивание - это еще одна полезная функция, которую пользователи могут использовать для предотвращения доступа к конфиденциальной информации.
- Организация файлов и страниц - Простые способы разделения и объединения файлов, создания портфолио в формате PDF, сравнения документов после распознавания текста, добавления/удаления/изменения порядка страниц, извлечения страниц и т.д.
- Уменьшение размера файла - Функция оптимизации PDF в PDFelement помогает архиваторам эффективно хранить большие объемы информации.
По этим и другим причинам PDFelement считается одним из лучших PDF-редакторов для распознавания текста и связанных с ним задач. Это программное обеспечение также является одной из самых доступных премиальных утилит по работе с PDF для небольших компаний, а также промышленных организаций, что делает его эффективным решением для компаний, образовательных учреждений и всех видов организаций в государственном и частном секторах.





